聊聊MySQL是如何处理排序的
本文分享自华为云社区《MySQL怎样处理排序⭐️如何优化需要排序的查询?》,作者:菜菜的后端私房菜。
前言
在MySQL的查询中常常会用到 order by 和 group by 这两个关键字
它们的相同点是都会对字段进行排序,那查询语句中的排序是如何实现的呢?
当使用的查询语句需要进行排序时有两种处理情况:
- 当前记录本来就是有序的,不需要进行排序
- 当前记录未保持顺序,需要排序
使用索引保证有序
对于第一种情况,常常是使用二级索引中索引列的有序来保证结果集有序,从而不需要进行排序
对于表a,为a2建立二级索引,那么在二级索引上a2就是有序的
CREATE TABLE `a` ( `a1` int(11) NOT NULL AUTO_INCREMENT, `a2` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL, `a3` varchar(255) DEFAULT NULL, PRIMARY KEY (`a1`), KEY `idx_a2` (`a2`) ) ENGINE=InnoDB AUTO_INCREMENT=76 DEFAULT CHARSET=utf8;
select * from a order by a.a2 limit 10
当优化器选择使用a2索引时,a2列的记录本身就是有序的,因此不需要再使用其他开销进行排序

当然,优化器也有可能不使用a2索引(当优化器认为使用a2回表开销太大时会使用全表扫描)

当优化器使用的索引上a2无序时,则会通过其他手段对结果进行排序
filesort
当执行计划的Extra附加信息中出现 Using filesort 时,会使用sort_buffer对结果进行排序
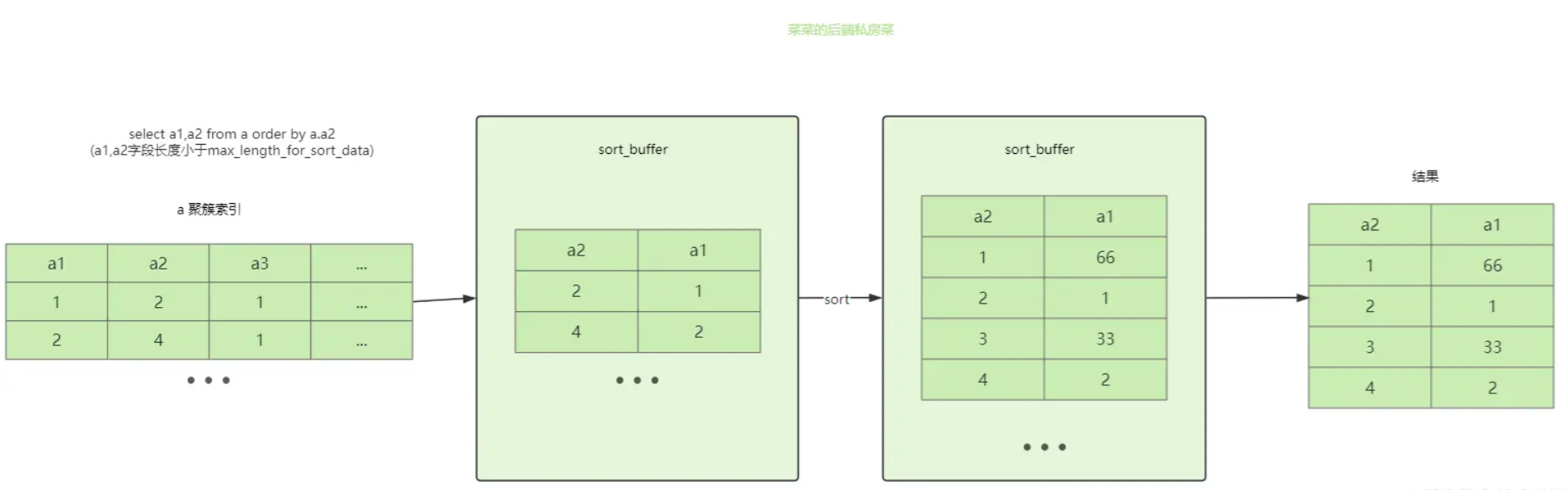
sort_buffer是一块用于排序的内存,sort_buffer可能存放查询需要的所有字段,也可能只存放需要排序的字段和主键
show variables like 'max_length_for_sort_data'
当查询需要的字段长度小于 max_length_for_sort_data 时,则会将查询需要的所有字段放入sort_buffer中,然后对需要排序的列进行排序,最后返回结果
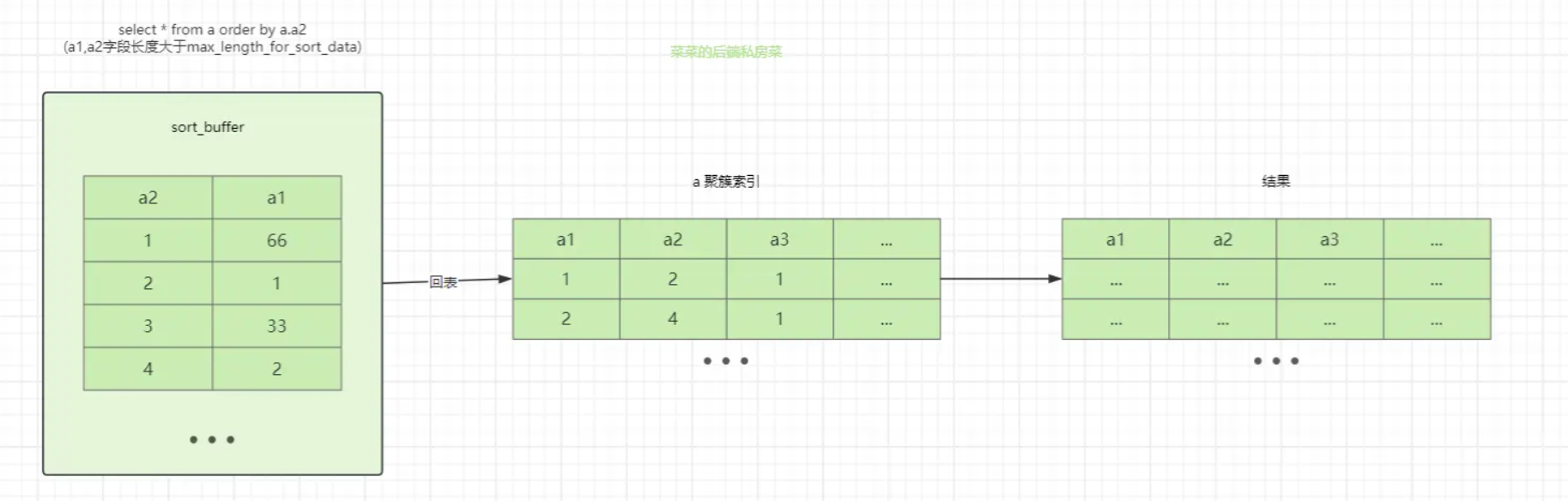
当查询需要的字段长度大于 max_length_for_sort_data 时,只会将需要排序的字段和主键值放入sort_buffer中,等到排序后再去查询聚簇索引获取需要查询的列(相当于又多了一次回表)
在sort_buffer中进行排序时,如果内存足够则会在内存中进行排序,如果内存不够则会使用磁盘的临时文件来辅助排序
开启 optimizer_trace 可以查看是否使用临时文件辅助排序
#开启优化器追踪 SET optimizer_trace='enabled=on'; #sql语句 select * from student order by student_name limit 10000; #查看优化器追踪的信息 SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G;
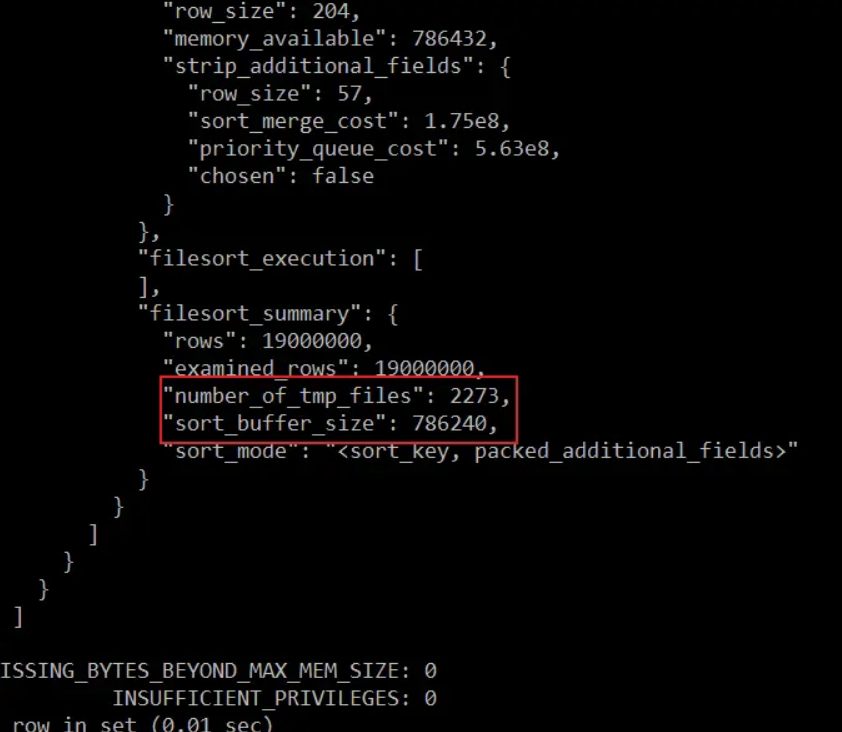
排序使用的算法是归并算法,先分割成多个小文件排序再进行合并
其中number_of_tmp_files 为使用到的临时文件数量,sort_buffer_size 为sort_buffer大小
因此当使用order by、group by等需要排序的关键字时,最好建立合适的索引
如果数据量小可以在sort buffer中排序,如果数据量太大还需要与磁盘交互
总结
当查询语句需要排序时会分为不用排序和需要排序两种情况
当使用的索引有序时则不用再进行排序,通过索引来保证有序
当使用的索引无序时则会使用sort_buffer进行排序,当查询字段的长度未超过限制时,sort_buffer中每条记录会存储需要查询的列
如果超过限制,则sort_buffer只会存储需要排序的列和主键值,排序后再通过主键值进行回表获取需要查询的列
当数据量太大不够在内存中排序完,会使用磁盘页辅助排序,使用归并算法将排序数据分散在多个页再合并
可以通过追踪优化器 optimizer_trace 分析内容查看辅助页的数量等信息
为需要排序的列建立合适的索引,避免使用磁盘页辅助排序
当无法使用索引时可以调整sort buffer 或 max_length_for_sort_data(谨慎)