《数据资产管理核心技术与应用》读书笔记-第四章:数据质量的技术实现(一)
《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,全书共分10章,第1章主要让读者认识数据资产,了解数据资产相关的基础概念,以及数据资产的发展情况。第2~8章主要介绍大数据时代数据资产管理所涉及的核心技术,内容包括元数据的采集与存储、数据血缘、数据质量、数据监控与告警、数据服务、数据权限与安全、数据资产管理架构等。第9~10章主要从实战的角度介绍数据资产管理技术的应用实践,包括如何对元数据进行管理以发挥出数据资产的更大潜力,以及如何对数据进行建模以挖掘出数据中更大的价值。
图书介绍:数据资产管理核心技术与应用
今天主要是给大家分享一下第四章的内容:
第四章的标题为数据质量的技术实现
内容思维导图如下:

在数据资产管理中,除了元数据和数据血缘外,数据质量也是很重要的一个环节,如下图所示,数据质量通常是指在数据处理的整个生命周期中,能否始终保持数据的完整性、一致性、准确性、可靠性、及时性等,我们只有知道了数据的质量,才能在数据质量差的时候,能去改进数据。《数据资产管理核心技术与应用》读书笔记-第四章:数据质量的技术实现
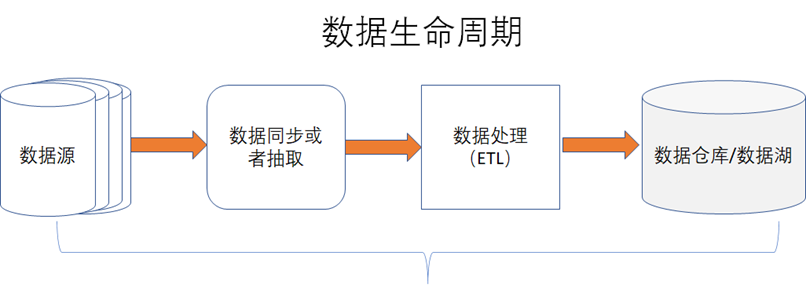
《数据资产管理核心技术与应用》读书笔记-第四章:数据质量的技术实现
- 完整性:数据是否有丢失,比如数据字段、数据量是否有丢失。
- 一致性:数据值是否完全一致,比如小数数据的精度是否出现丢失。
- 准确性:数据含义是否准确,比如数据字段注释是否准确。
- 可靠性:比如数据存储是否可靠,是否做了数据灾备等。
- 及时性:数据是否出现延迟或者堵塞导致没有及时入数据仓库或者数据湖。
正是因为数据质量的重要性,所以在国际上有专门对数据质量进行国际标准定义,比如ISO 8000数据质量系列国际标准中就详细的描述了数据质量如何衡量以及如何进行认证等,包含了数据质量的特性、特征以及如何进行数据质量的管理、评估等。在ISO 8000中共发布了21个标准,在网址:https://std.samr.gov.cn/gj/std?op=ISO中可以查询到ISO 8000质量标准,如下4-0-2所示

和数据质量相关的主要内容包括如下:
- 1)、ISO 8000-1:2022 Data quality-Part 1: Overview
- 2)、ISO 8000-2:2022 Data quality-Part 2: Vocabulary
- 3)、ISO 8000-8:2015 Data quality-Part 8: Information and data quality: Concepts and measuring
- 4)、ISO/TS 8000-60:2017 Data quality-Part 60:Data quality management: Overview
- 5)、ISO 8000-61:2016 Data quality-Part 61: Data quality management: Process reference model
- 6)、ISO 8000-62:2018 Data quality-Part 62: Data quality management: Organizational process maturity assessment: Application of standards relating to process assessment
- 7)、ISO 8000-63:2019 Data quality-Part 63: Data quality management: Process measurement
- 8)、ISO 8000-64:2022 Data quality-Part 64: Data quality management: Organizational process maturity assessment: Application of the Test Process Improvement method
- 9)、ISO 8000-65:2020 Data quality -Part 65:Data quality management: Process measurement questionnaire
- 10)、ISO 8000-66:2021 Data quality-Part 66: Data quality management: Assessment indicators for data processing in manufacturing operations
- 11)、ISO/TS 8000-81:2021 Data quality-Part 81: Data quality assessment: Profiling
- 12)、ISO/TS8000-82:2022 Data quality-Part 82:Data quality assessment: Creating data rules
- 13)、ISO 8000-100:2016 Data quality-Part 100: Master data: Exchange of characteristic data: Overview
- 14)、ISO 8000-110:2021 Data quality-Part 110: Master data: Exchange of characteristic data: Syntax, semantic encoding, and conformance to data specification
- 15)、ISO 8000-115:2018 Data quality-Part 115: Master data: Exchange of quality identifiers: Syntactic, semantic and resolution requirements
- 16)、ISO 8000-116:2019 Data quality-Part 116: Master data: Exchange of quality identifiers: Application of ISO 8000-115 to authoritative legal entity identifiers
- 17)、ISO 8000-120:2016 Data quality -Part 120: Master data: Exchange of characteristic data: Provenance
- 18)、ISO 8000-130:2016 Data quality-Part 130: Master data: Exchange of characteristic data: Accuracy
- 19)、ISO 8000-140:2016 Data quality- Part 140: Master data: Exchange of characteristic data: Completeness
- 20)、ISO 8000-150:2022 Data quality -Part 150: Data quality management: Roles and responsibilities
- 21)、ISO/TS 8000-311:2012 Data quality-Part 311: Guidance for the application of product data quality for shape (PDQ-S)
1、质量数据采集的技术实现
不管是在数据仓库还是数据湖中,一开始我们都是不知道数据的质量情况的,需要通过一定的规则定期的到数据湖或者数据仓库中去采集数据的质量,这个规则是允许用户自己去进行配置的,通常的流程如下图所示。
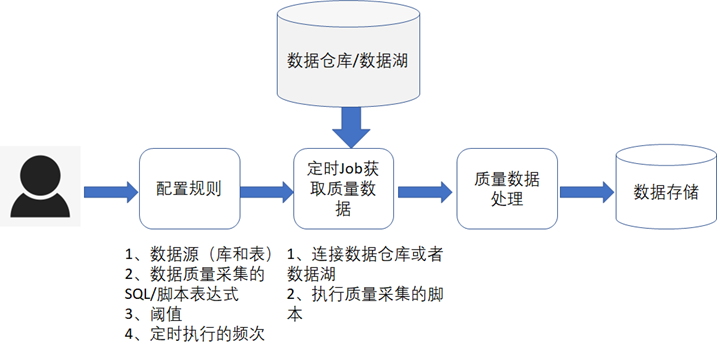
对于一些通用的规则,可以做成规则模板,然后用户可以直接选择某个规则进行质量数据采集,常见的通用规则如下表所示。
《数据资产管理核心技术与应用》读书笔记-第四章:数据质量的技术实现
|
规则 |
描述 |
|
表字段的空值率 |
采集指定表的指定字段为空的比率 |
|
表字段的异常率 |
采集指标表的指定字段值的异常率,比如性别字段,只可能为男或者女,对于别的值就是异常值,我们可以根据规则统计出异常值的比率,哪些值是异常值当然也需要支持自定义维护 |
|
表字段数据格式异常率 |
采集指标表的指定字段值的数据格式异常率,比如时间格式或者手机号格式不符合指定规则的就是异常数据,我们可以计算出这些格式异常的比率 |
|
表字段数据的重复率 |
采集指定表的指定字段值的重复率,比如某些字段的值是不允许重复的,出现重复时就是异常 |
|
表字段的缺失率 |
采集指定表的字段数量是否和预期的字段数量一致,如果不一致,就是出现了字段缺失,就可以统计出字段的缺失率 |
|
表数据入库的及时率 |
采集指定的表数据的入库时间和当前系统时间的差异,然后来计算出数据的及时性以及及时率 |
|
表记录的丢失率 |
1、 采集指定的表数据的记录数,然后和预期的数据量或者源表中的数据量进行比较,计算出数据记录的丢失率 2、 采集指定的表数据的记录数,然后和周或者月平均值进行比较,判断数据记录数是否低于正常标准,从而判断是否存在丢失。 |
除了通用规则外,肯定还需要支持自定义的规则,自定义的规则可以允许用户自己编写SQL脚本、Python语言脚本或者scala 语言脚本。
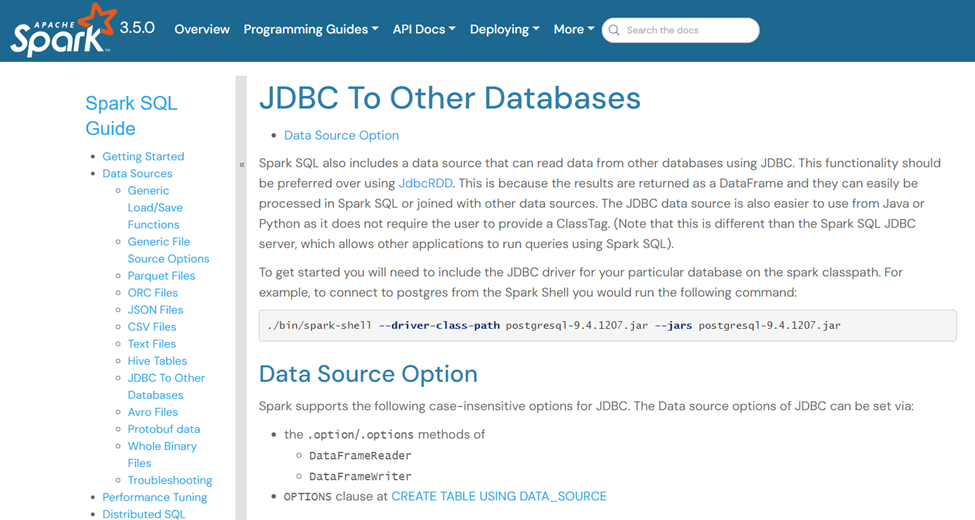
- SQL脚本:一般是指通过JDBC的方式直接提交和运行SQL脚本从而获取数据质量结果,常见的关系型数据库,如MySQL、SQLServer等都是支持JDBC的,并且Hive也是支持JDBC连接的,另外还可以通过SparkSQL Job的方式来运行SQL脚本,如下图所示。

总结下来就是:如果数据库或者数据仓库本身支持JDBC 协议,那么可以直接通过JDBC协议运行SQL语句。如果不支持的话,那么可以通过SparkSQL job的方式进行过渡,SparkSQL 本身支持连接到Hive、Hudi等数据仓库或者数据湖,也支持通过JDBC的方式连接到其他的数据库。在官方网站地址: https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html中有明确的介绍,如下图所示。
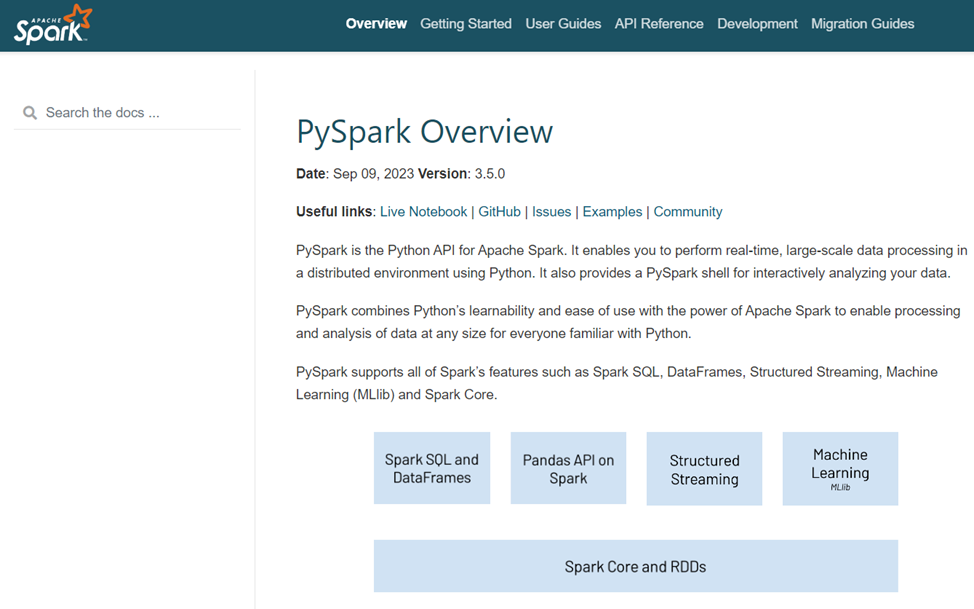
- Python脚本:Python 是一种常用的脚本语言,由于SQL 脚本只支持一些直接用SQL语句就可以查询到的数据结果,对于一些复杂的场景或者SQL语句无法支持的场景,可以使用Python脚本,并且Spark也是支持Python语言的,如下图所示。

PySpark的相关介绍可以参考网址:https://spark.apache.org/docs/latest/api/python/index.html,如下图所示。
《数据资产管理核心技术与应用》读书笔记-第四章:数据质量的技术实现
- Scala脚本:Spark 底层本身主要是通过Scala语言编写的代码实现的,很多大数据开发者都很热衷于使用Scala语言,所以对于Spark Job 采集数据质量时,也可以编写Scala脚本,如下图所示。

对于采集质量数据时,定时Job的技术选型,笔者在这里推荐Apache DolphinSchedur这个大数据任务调度平台。Apache DolphinSchedur是一个分布式、易于扩展的可视化工作流任务调度开源平台,解决了复杂的大数据任务依赖关系,并支持在各种大数据应用程序的DataOPS中任意编排任务节点之间的关联关系其以定向非循环图(DAG)流模式组装任务,可以及时监控任务的执行状态,并支持重试、指定节点恢复失败、暂停、恢复和终止任务等操作。官方网址为:https://dolphinscheduler.apache.org/en-us,如下图所示。
Apache DolphinSchedur 支持二次开发,其Github地址为:https://github.com/apache/dolphinscheduler
相关的部署文档的地址为:https://dolphinscheduler.apache.org/en-us/docs/3.2.0/installation_menu
如下图所示,为官方在网址https://dolphinscheduler.apache.org/en-us/docs/3.2.0/architecture/design中提供的技术实现架构图。
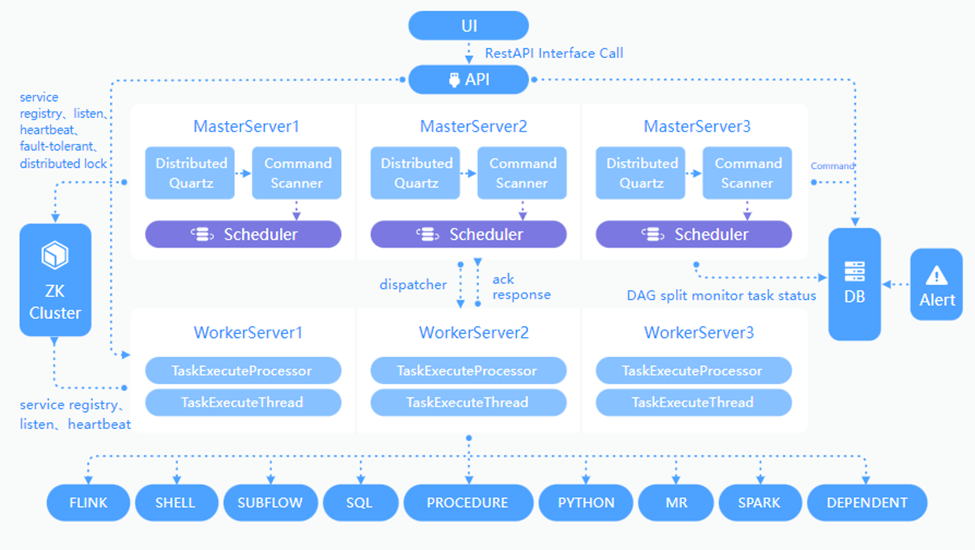
从图中可以看到,其支持SQL、Python、Spark等任务节点,正好是我们所需要的,而且该平台是支持分布式部署和调度的,所以不存在任何的性能瓶颈,因为分布式系统支持横向或者纵向的扩展。
Apache DolphinSchedur 还提供了API的方式进行访问,官方API文档地址为:https://dolphinscheduler.apache.org/en-us/docs/3.2.0/guide/api/open-api。
最终采集质量数据的技术实现架构图如下图所示。
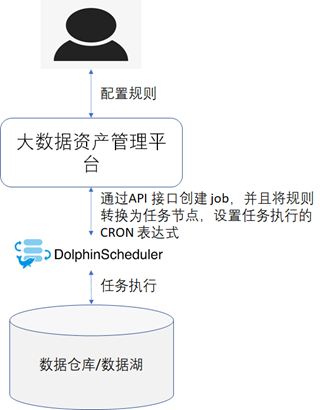
未完待续......《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,读书笔记-第四章:数据质量的技术实现.