解锁Spring组件扫描的新视角
本文分享自华为云社区《Spring高手之路10——解锁Spring组件扫描的新视角》,作者: 砖业洋__。
首先,我们将探讨一些Spring框架中IOC(Inversion of Control)的高级特性,特别是组件扫描的相关知识。组件扫描是Spring框架中一个重要的特性,它可以自动检测并实例化带有特定注解(如@Component, @Service, @Controller等)的类,并将它们注册为Spring上下文中的bean。这里,我们会通过一些详细的例子来阐明这些概念,并且展示如何在实际的代码中使用这些特性。
1. 组件扫描路径
@ComponentScan注解是用于指定Spring在启动时需要扫描的包路径,从而自动发现并注册组件。
我们设置组件扫描路径包括两种方式:
-
直接指定包名:如
@ComponentScan("com.example.demo"),等同于@ComponentScan(basePackages = {"com.example.demo"}),Spring会扫描指定包下的所有类,并查找其中带有@Component、@Service、@Repository等注解的组件,然后将这些组件注册为Spring容器的bean。 -
指定包含特定类的包:如
@ComponentScan(basePackageClasses = {ExampleService.class}),Spring会扫描ExampleService类所在的包以及其所有子包。
接下来,给出了一个完整的例子,说明如何使用第二种方式来设置组件扫描路径。这可以通过设置@ComponentScan的basePackageClasses属性来实现。例如:
@Configuration @ComponentScan(basePackageClasses = {ExampleService.class}) public class BasePackageClassConfiguration { }
以上代码表示,Spring会扫描ExampleService类所在的包以及其所有子包。
全部代码如下:
首先,我们创建一个名为ExampleService的服务类
package com.example.demo.service; import org.springframework.stereotype.Service; @Service public class ExampleService { }
接着在bean目录下创建DemoDao
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class DemoDao { }
然后在配置类中设置组件扫描路径
package com.example.demo.configuration; import com.example.demo.service.ExampleService; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.Configuration; @Configuration @ComponentScan(basePackageClasses = ExampleService.class) public class BasePackageClassConfiguration { }
我们还会创建一个名为DemoApplication的类,这个类的作用是启动Spring上下文并打印所有注册的bean的名称。
package com.example.demo; import com.example.demo.configuration.BasePackageClassConfiguration; import org.springframework.context.annotation.AnnotationConfigApplicationContext; import java.util.Arrays; public class DemoApplication { public static void main(String[] args) { AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(BasePackageClassConfiguration.class); String[] beanDefinitionNames = ctx.getBeanDefinitionNames(); Arrays.stream(beanDefinitionNames).forEach(System.out::println); } }
运行上述DemoApplication类的main方法,就会在控制台上看到所有注册的bean的名称,包括我们刚刚创建的ExampleService。

现在,如果我们在ExampleService类所在的包或者其任意子包下创建一个新的类(例如TestService),那么这个组件类也会被自动注册为一个bean。这就是basePackageClasses属性的作用:它告诉Spring要扫描哪些包以及其子包。
package com.example.demo.service; import org.springframework.stereotype.Service; @Service public class TestService { }
如果再次运行DemoApplication类的main方法,就会看到TestService也被打印出来,说明它也被成功注册为了一个bean。

我们可以看到这个DemoDao始终没有被扫描到,我们看一下@ComponentScan注解的源码

可以看到basePackageClasses属性这是一个数组类型的,有人会疑问了,刚刚我们写的@ComponentScan(basePackageClasses = ExampleService.class),这没有用到数组啊,为什么这里还能正常运行呢?
如果数组只包含一个元素,可以在赋值时省略数组的大括号 {},这是Java的一种语法糖。在这种情况下,编译器会自动把该元素包装成一个数组。
例如,以下两种写法是等价的:
@ComponentScan(basePackageClasses = {ExampleService.class})
和
@ComponentScan(basePackageClasses = ExampleService.class)
在上面两种情况下,ExampleService.class都会被包装成一个只包含一个元素的数组。这是Java语法的一个便利特性,使得代码在只有一个元素的情况下看起来更加简洁。
那么为了DemoDao组件被扫描到,我们可以在basePackageClasses 属性加上DemoDao类,这样就可以扫描DemoDao组件所在的包以及它的子包。
package com.example.demo.configuration; import com.example.demo.bean.DemoDao; import com.example.demo.service.ExampleService; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.Configuration; @Configuration @ComponentScan(basePackageClasses = {ExampleService.class, DemoDao.class}) public class BasePackageClassConfiguration { }
运行结果

@ComponentScan注解的源码还有不少,后面我们用到再说
2. 按注解过滤组件(包含)
除了基本的包路径扫描,Spring还提供了过滤功能,允许我们通过设定过滤规则,只包含或排除带有特定注解的类。这个过滤功能对于大型项目中的模块划分非常有用,可以精细控制Spring的组件扫描范围,优化项目启动速度。
在Spring中可以通过@ComponentScan的includeFilters属性来实现注解包含过滤,只包含带有特定注解的类。
在下面这个例子中,我们将创建一些带有特定注解的组件,并设置一个配置类来扫描它们。
全部代码如下:
创建一个新的注解Species:
package com.example.demo.annotation; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) public @interface Species { }
接下来,我们将创建三个不同的组件,其中两个包含Species注解:
package com.example.demo.bean; import com.example.demo.annotation.Species; import org.springframework.stereotype.Component; @Species public class Elephant { }
Elephant 类被@Species修饰,没有@Component修饰。
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Monkey { }
Monkey只被@Component修饰
package com.example.demo.bean; import com.example.demo.annotation.Species; import org.springframework.stereotype.Component; @Component @Species public class Tiger { }
如上所示,Tiger有@Component和@Species修饰。
接着,我们需要创建一个配置类,用于扫描和包含有Species注解的组件:
package com.example.demo.configuration; import com.example.demo.annotation.Species; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.ComponentScan.Filter; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.FilterType; @Configuration @ComponentScan(basePackages = "com.example.demo", includeFilters = @Filter(type = FilterType.ANNOTATION, classes = Species.class), useDefaultFilters = false) public class FilterConfiguration { }
在这个配置类中,我们设置了 @ComponentScan 注解的 includeFilters 属性,FilterType.ANNOTATION代表按注解过滤,这里用于扫描包含所有带有 Species 注解的组件。注意,useDefaultFilters = false 表示禁用了默认的过滤规则,只会包含标记为 Species 的组件。
有人可能会疑问了,useDefaultFilters = false 表示禁用了默认的过滤规则,什么是默认的过滤规则?
在Spring中,当使用@ComponentScan注解进行组件扫描时,Spring提供了默认的过滤规则。这些默认规则包括以下几种类型的注解:
- @Component
- @Repository
- @Service
- @Controller
- @RestController
- @Configuration
默认不写useDefaultFilters属性的情况下,useDefaultFilters属性的值为true,Spring在进行组件扫描时会默认包含以上注解标记的组件,如果将useDefaultFilters设置为false,Spring就只会扫描明确指定过滤规则的组件,不再包括以上默认规则的组件。所以,useDefaultFilters = false是在告诉Spring我们只想要自定义组件扫描规则。
最后,我们创建一个主程序,来实例化应用上下文并列出所有的Bean名称:
package com.example.demo; import com.example.demo.configuration.FilterConfiguration; import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class DemoApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(FilterConfiguration.class); String[] beanNames = ctx.getBeanDefinitionNames(); for (String beanName : beanNames) { System.out.println(beanName); } } }
当我们运行这个程序时,会看到输出的Bean名字只包括被Species注解标记的类。在这个例子中会看到 Tiger 和 Elephant,但不会看到 Monkey,因为我们的配置只包含了被 Species 注解的类。
运行结果:
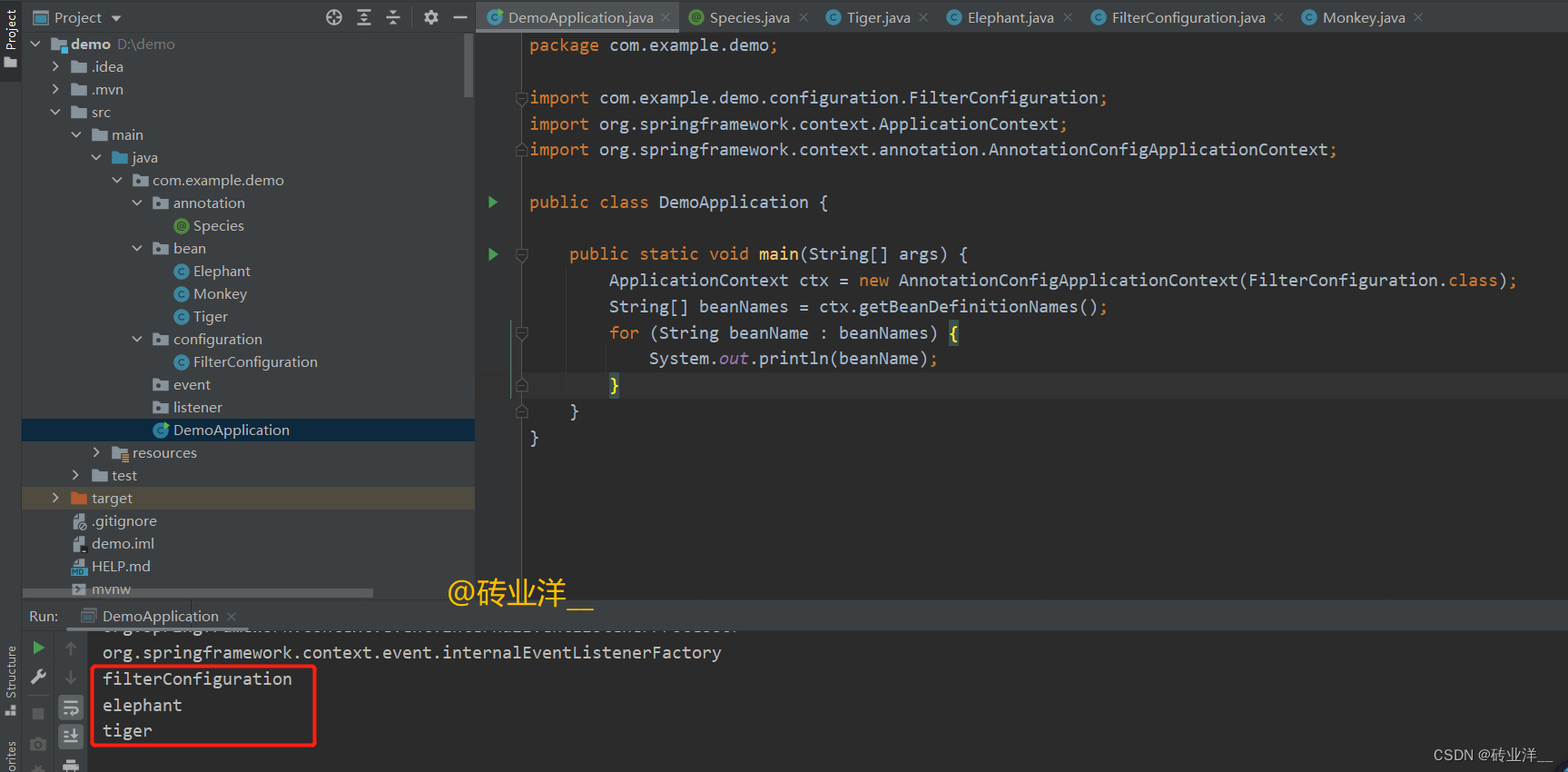
如果useDefaultFilters属性设置为true,那么运行程序时输出的Bean名字将会包括Monkey。
总结:上面介绍了如何使用Spring的@ComponentScan注解中的includeFilters属性和useDefaultFilters属性来过滤并扫描带有特定注解的类。通过自定义注解和在配置类中设置相关属性,可以精确地控制哪些类被Spring容器扫描和管理。如果设置useDefaultFilters为false,则Spring只扫描被明确指定过滤规则的组件,不再包含默认规则(如@Component、@Service等)的组件。
3. 按注解过滤组件(排除)
在Spring框架中,我们不仅可以通过@ComponentScan注解的includeFilters属性设置包含特定注解的类,还可以通过excludeFilters属性来排除带有特定注解的类。这个功能对于我们自定义模块的加载非常有用,我们可以通过这种方式,精确控制哪些组件被加载到Spring的IOC容器中。下面我们将通过一个具体的示例来说明如何使用@ComponentScan的excludeFilters属性来排除带有特定注解的类。
全部代码如下:
首先,创建一个注解Exclude:
package com.example.demo.annotation; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) public @interface Exclude { }
定义三个类Elephant、Monkey 、Tiger
package com.example.demo.bean; import com.example.demo.annotation.Exclude; import org.springframework.stereotype.Component; @Component @Exclude public class Elephant { }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Monkey { }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Tiger { }
注意,这几个类都标记为 @Component,Elephant类上有@Exclude注解。
接下来,我们创建配置类 FilterConfiguration,在其中使用 @ComponentScan 注解,并通过 excludeFilters 属性排除所有标记为 @Exclude 的类:
package com.example.demo.configuration; import com.example.demo.annotation.Exclude; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.FilterType; @Configuration @ComponentScan(basePackages = "com.example.demo", excludeFilters = @ComponentScan.Filter(type = FilterType.ANNOTATION, classes = Exclude.class)) public class FilterConfiguration { }
这样,在Spring IOC容器中,只有 Tiger 和 Monkey 类会被扫描并实例化,因为 Elephant 类被 @Exclude 注解标记,而我们在 FilterConfiguration 类中排除了所有被 @Exclude 注解标记的类。
主程序为:
package com.example.demo; import com.example.demo.configuration.FilterConfiguration; import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class DemoApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(FilterConfiguration.class); String[] beanNames = ctx.getBeanDefinitionNames(); for (String beanName : beanNames) { System.out.println(beanName); } } }
运行结果:
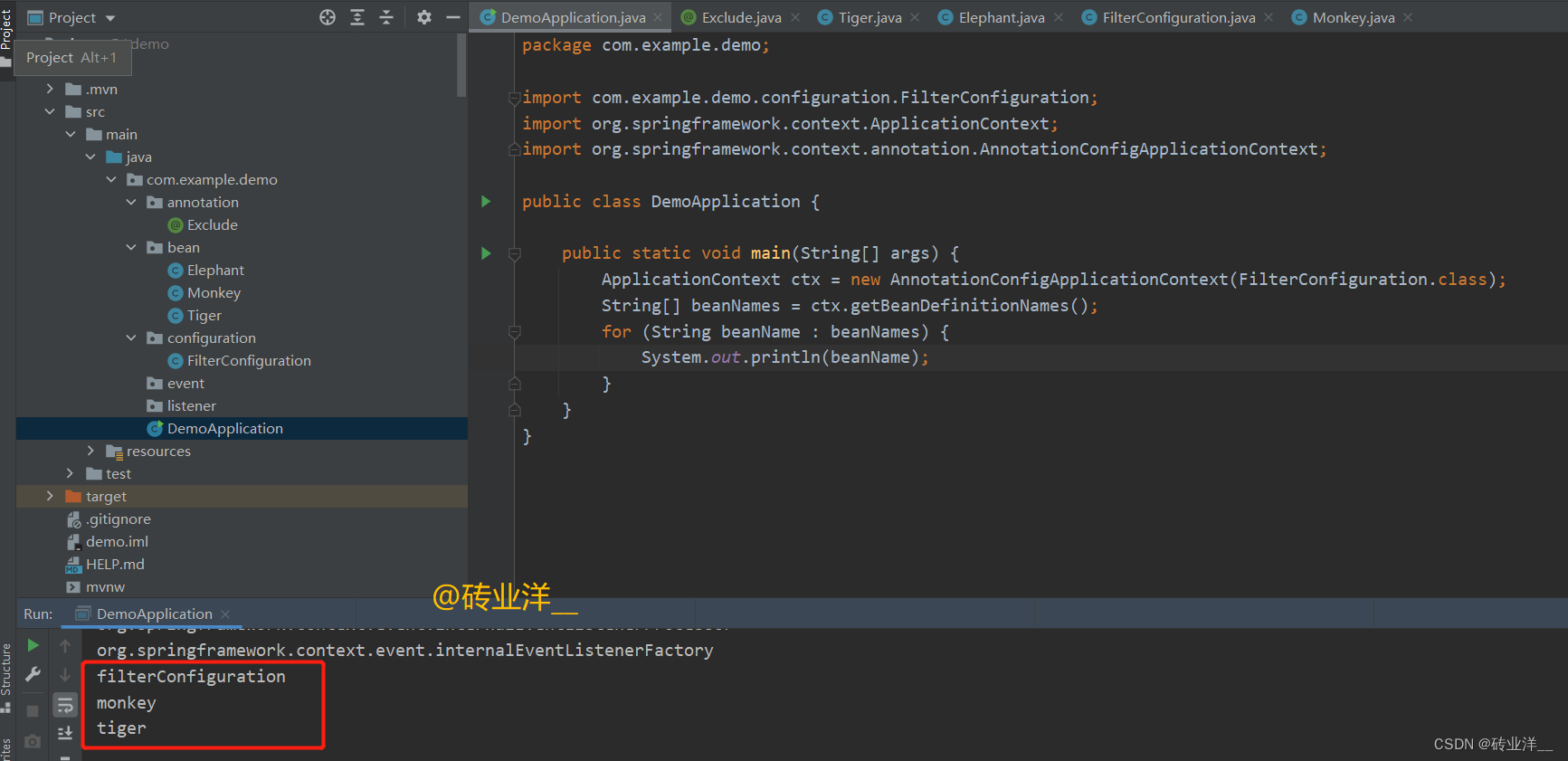
总结:这小节主要讲解了如何在Spring框架中通过@ComponentScan注解的excludeFilters属性进行注解过滤,以精确控制加载到Spring IOC容器中的组件。在本小节的示例中,我们首先创建了一个名为Exclude的注解,然后定义了三个类Elephant、Monkey、和Tiger,它们都被标记为@Component,其中Elephant类上还有一个@Exclude注解。接下来,我们创建了一个配置类FilterConfiguration,其中使用了@ComponentScan注解,并通过excludeFilters属性排除了所有标记为@Exclude的类。因此,当程序运行时,Spring IOC容器中只有Tiger和Monkey类会被扫描并实例化,因为Elephant类被@Exclude注解标记,所以被排除了。
4. 通过正则表达式过滤组件
在Spring框架中,除了可以通过指定注解来进行包含和排除类的加载,我们还可以利用正则表达式来对组件进行过滤。这种方式提供了一种更灵活的方式来选择需要被Spring IOC容器管理的类。具体来说,可以利用正则表达式来包含或者排除名称符合某个特定模式的类。下面,我们将通过一个具体的例子来展示如何使用正则表达式过滤来只包含类名以特定字符串结尾的类。
下面的例子将演示如何只包含类名以Tiger结尾的类。
全部代码如下:
定义三个类Tiger 、Elephant 、Monkey
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Elephant { }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Monkey { }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Tiger { }
接着我们创建配置类 FilterConfiguration,使用 @ComponentScan 注解,并通过 includeFilters 属性来包含类名以 Tiger 结尾的类:
package com.example.demo.configuration; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.FilterType; @Configuration @ComponentScan(basePackages = "com.example.demo", useDefaultFilters = false, includeFilters = @ComponentScan.Filter(type = FilterType.REGEX, pattern = ".*Tiger")) public class FilterConfiguration { }
在上述示例中,我们使用 FilterType.REGEX 过滤类型,并指定要包含的正则表达式模式 ".*Tiger"。结果只会有 Tiger 类会被Spring的IOC容器扫描并实例化,因为只有 Tiger 类的类名满足正则表达式 ".*Tiger"。这里. 代表任意单个字符(除了换行符),* 代表前一个字符重复任意次,.* 组合起来表示匹配任意个任意字符。
主程序:
package com.example.demo; import com.example.demo.configuration.FilterConfiguration; import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class DemoApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(FilterConfiguration.class); String[] beanNames = ctx.getBeanDefinitionNames(); for (String beanName : beanNames) { System.out.println(beanName); } } }
运行结果

总结:本小节介绍了如何在Spring框架中使用正则表达式对组件进行过滤,以选择哪些类应被Spring IOC容器管理。在所给示例中,首先定义了三个类Elephant、Monkey和Tiger。然后创建了一个配置类FilterConfiguration,使用了@ComponentScan注解,并通过includeFilters属性设置了一个正则表达式" .*Tiger",用于选择类名以"Tiger"结尾的类。所以在运行主程序时,Spring的IOC容器只会扫描并实例化Tiger类,因为只有Tiger类的类名满足正则表达式" .*Tiger"。
5. Assignable类型过滤组件
"Assignable类型过滤"是Spring框架在进行组件扫描时的一种过滤策略,该策略允许我们指定一个或多个类或接口,然后Spring会包含或排除所有可以赋值给这些类或接口的类。如果我们指定了一个特定的接口,那么所有实现了这个接口的类都会被包含(或者排除)。同样,如果指定了一个具体的类,那么所有继承自这个类的类也会被包含(或者排除)。
在下面的例子中,我们将使用 “Assignable类型过滤” 来包含所有实现了 Animal 接口的类。
全部代码如下:
首先,我们定义一个 Animal 接口
package com.example.demo.bean; public interface Animal { }
接着定义三个类:Elephant 、 Monkey和Tiger,其中Tiger没有实现Animal接口
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Elephant implements Animal { }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Monkey implements Animal { }
package com.example.demo.bean import org.springframework.stereotype.Component; @Component public class Tiger { }
然后,我们创建一个 FilterConfiguration类并使用 @ComponentScan 来扫描所有实现了 Animal 接口的类。
package com.example.demo.configuration; import com.example.demo.bean.Animal; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.FilterType; @Configuration @ComponentScan(basePackages = "com.example.demo", useDefaultFilters = false, includeFilters = @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, classes = Animal.class)) public class FilterConfiguration { }
这种过滤方式在@ComponentScan注解中通过FilterType.ASSIGNABLE_TYPE来使用,这里Spring将只扫描并管理所有实现了Animal接口的类。
最后,我们创建一个主程序来测试:
package com.example.demo; import com.example.demo.configuration.FilterConfiguration; import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class DemoApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(FilterConfiguration.class); String[] beanNames = ctx.getBeanDefinitionNames(); for (String beanName : beanNames) { System.out.println(beanName); } } }
运行结果:

这里也可以看到,只有实现了 Animal 接口的类才会被 Spring 的 IoC 容器扫描并实例化,其他的 @Component 类没有实现 Animal 接口的bean将不会被扫描和实例化。
总结:本小节介绍了Spring框架中的"Assignable类型过滤",这是一种可以指定一个或多个类或接口进行组件扫描的过滤策略。Spring会包含或排除所有可以赋值给这些类或接口的类。在本小节的例子中,首先定义了一个Animal接口,然后定义了三个类Elephant、Monkey和Tiger,其中Elephant和Monkey实现了Animal接口,而Tiger没有。然后创建了一个FilterConfiguration类,使用了@ComponentScan注解,并通过includeFilters属性和FilterType.ASSIGNABLE_TYPE类型来指定扫描所有实现了Animal接口的类。因此,当运行主程序时,Spring的IOC容器只会扫描并实例化实现了Animal接口的Elephant和Monkey类,未实现Animal接口的Tiger类不会被扫描和实例化。
6. 自定义组件过滤器
Spring也允许我们定义自己的过滤器来决定哪些组件将被Spring IoC容器扫描。为此,我们需要实现TypeFilter接口,并重写match()方法。在match()方法中,我们可以自定义选择哪些组件需要被包含或者排除。
全部代码如下:
新增一个接口Animal
package com.example.demo.bean; public interface Animal { String getType(); }
定义几个类,实现Animal接口
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Elephant implements Animal { public String getType() { return "This is a Elephant."; } }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Monkey implements Animal { public String getType() { return "This is an Monkey."; } }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Tiger implements Animal { public String getType() { return "This is a Tiger."; } }
package com.example.demo.bean; import org.springframework.stereotype.Component; @Component public class Tiger2 { public String getType() { return "This is a Tiger2."; } }
Tiger2 没实现Animal接口,后面用来对比。
下面我们先个自定义一个过滤器CustomFilter,它实现了TypeFilter接口,这个过滤器会包含所有实现了Animal接口并且类名以"T"开头的类:
package com.example.demo.filter; import com.example.demo.bean.Animal; import org.springframework.core.type.ClassMetadata; import org.springframework.core.type.classreading.MetadataReader; import org.springframework.core.type.classreading.MetadataReaderFactory; import org.springframework.core.type.filter.TypeFilter; import java.io.IOException; import java.util.Arrays; public class CustomFilter implements TypeFilter { @Override public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException { ClassMetadata classMetadata = metadataReader.getClassMetadata(); // 如果全限定类名以 "T" 开头并且实现了 "Animal" 接口 return classMetadata.getClassName().startsWith("com.example.demo.bean.T") && Arrays.asList(classMetadata.getInterfaceNames()).contains(Animal.class.getName()); } }
如果 match 方法返回 true,那么 Spring 将把这个类视为候选组件,还需满足其他条件才能创建bean,如果这个类没有使用@Component、@Service等注解,那么即使过滤器找到了这个类,Spring也不会将其注册为bean。因为Spring依然需要识别类的元数据(如:@Component、@Service等注解)来确定如何创建和管理bean。反之,如果 match 方法返回 false,那么 Spring 将忽略这个类。
在match方法中
-
metadataReader.getClassMetadata()返回一个ClassMetadata对象,它包含了关于当前类的一些元数据信息,例如类名、是否是一个接口、父类名等。 -
classMetadata.getClassName()返回当前类的全限定类名,也就是包括了包名的类名。
在 match 方法中,我们检查了当前类的全限定名是否以 "com.example.demo.bean.T" 开头,并且当前类是否实现了 "Animal" 接口。如果满足这两个条件,match 方法就返回 true,Spring会将这个类视为候选组件。如果这两个条件有任何一个不满足,match 方法就返回 false,Spring就会忽略这个类,不会将其视为候选组件。
然后,在我们的FilterConfiguration 中,使用FilterType.CUSTOM类型,并且指定我们刚才创建的CustomFilter类:
package com.example.demo.configuration; import com.example.demo.filter.CustomFilter; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.FilterType; @Configuration @ComponentScan(basePackages = "com.example.demo", useDefaultFilters = false, includeFilters = @ComponentScan.Filter(type = FilterType.CUSTOM, classes = CustomFilter.class)) public class FilterConfiguration { }
这样,当Spring IoC容器进行扫描的时候,只有类名以"T"开头并且实现了Animal接口的组件才会被包含。在我们的例子中,只有Tiger类会被包含,Tiger2、Elephant和Monkey类将被排除。
主程序:
package com.example.demo; import com.example.demo.configuration.FilterConfiguration; import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class DemoApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(FilterConfiguration.class); String[] beanNames = ctx.getBeanDefinitionNames(); for (String beanName : beanNames) { System.out.println(beanName); } } }
运行结果:
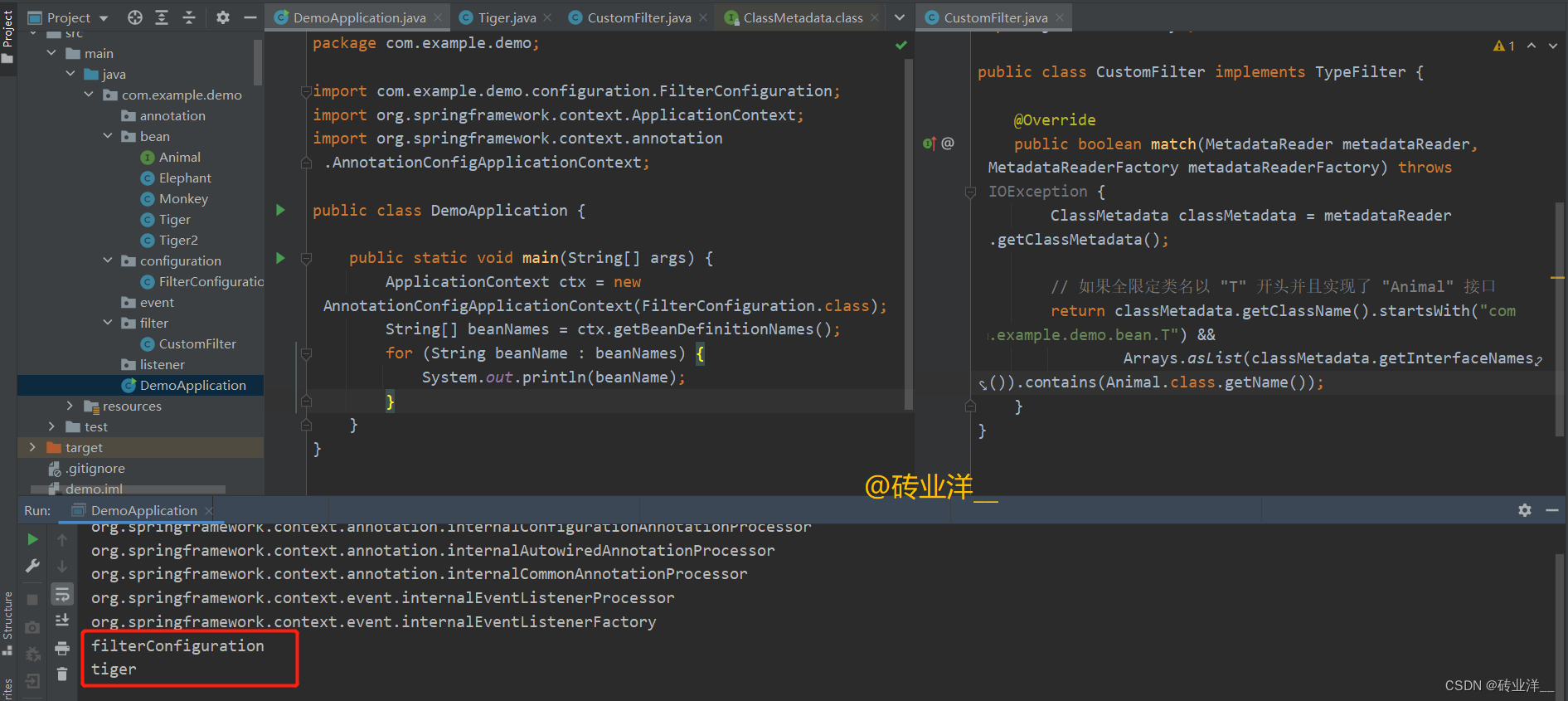
调试会发现,match方法在不停的回调。其实match 方法的调用次数和 Spring 应用上下文中的 Bean 定义数量是相关的,当我们使用 @ComponentScan 进行包扫描时,Spring 会遍历指定包(及其子包)下的所有类,对每个类进行分析以决定是否需要创建对应的 Bean。
当我们使用 @ComponentScan.Filter 定义自定义的过滤器时,Spring 会为每个遍历到的类调用过滤器的 match 方法,以决定是否需要忽略这个类。因此,match 方法被调用的次数等于 Spring 扫描到的类的数量,不仅包括最终被创建为 Bean 的类,也包括被过滤器忽略的类。
这个行为可能受到一些其他配置的影响。例如,如果 Spring 配置中使用了懒加载 (@Lazy),那么 match 方法的调用可能会被延迟到 Bean 首次被请求时。
总结:本小节介绍了如何在Spring框架中创建和使用自定义过滤器,以决定哪些组件将被Spring IoC容器视为候选组件。通过实现TypeFilter接口并重写其match()方法,可以根据自定义的条件决定哪些类会被包含在候选组件的列表中。在这个例子中,我们创建了一个自定义过滤器,只有以"T"开头且实现了Animal接口的类才会被标记为候选组件。当Spring进行包扫描时,会遍历所有的类,并对每个类调用过滤器的match()方法,这个方法的调用次数等于Spring扫描到的类的数量。然后,只有那些同时满足过滤器条件并且被Spring识别为组件的类(例如,使用了@Component或@Service等注解),才会被实例化为Bean并被Spring IoC容器管理。如果配置了懒加载,那么Bean的实例化可能会被延迟到Bean首次被请求时。
7. 组件扫描的其他特性
Spring 的组件扫描机制提供了一些强大的特性,我们来逐一讲解。
7.1 组合使用组件扫描
Spring 提供了 @ComponentScans 注解,让我们能够组合多个 @ComponentScan 使用,这样可以让我们在一次操作中完成多次包扫描。
@ComponentScans的主要使用场景是当需要对Spring的组件扫描行为进行更精细的控制时,可以在同一个应用程序中扫描两个完全独立的包,也可以在应用多个独立的过滤器来排除或包含特定的组件。

可以看到@ComponentScans注解接收了一个ComponentScan数组,也就是一次性组合了一堆 @ComponentScan 注解。
让我们通过一个例子来看看如何使用 @ComponentScans 来组合多个 @ComponentScan。
全部代码如下:
首先,我们定义两个简单的类,分别在 com.example.demo.bean1 和 com.example.demo.bean2 包中:
package com.example.demo.bean1; import org.springframework.stereotype.Component; @Component public class BeanA { }
package com.example.demo.bean2; import org.springframework.stereotype.Component; @Component public class BeanB { }
然后,我们在配置类中使用 @ComponentScans 来一次性扫描这两个包:
package com.example.demo.configuration; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.ComponentScans; import org.springframework.context.annotation.Configuration; @Configuration @ComponentScans({ @ComponentScan("com.example.demo.bean1"), @ComponentScan("com.example.demo.bean2") }) public class AppConfig { }
最后,我们可以测试一下是否成功地扫描到了这两个类:
package com.example.demo; import com.example.demo.bean1.BeanA; import com.example.demo.bean2.BeanB; import com.example.demo.configuration.AppConfig; import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class DemoApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(AppConfig.class); BeanA beanA = ctx.getBean(BeanA.class); BeanB beanB = ctx.getBean(BeanB.class); System.out.println("beanA = " + beanA); System.out.println("beanB = " + beanB); } }
运行上述 main 方法,BeanA 和 BeanB 就成功地被扫描并注入到了 Spring 的 ApplicationContext 中。
运行结果:

总结:本小节介绍了Spring包扫描机制的一个重要特性,即能够使用@ComponentScans注解进行组合包扫描。这个特性允许在一次操作中完成多次包扫描,实现对Spring组件扫描行为的精细控制。例如,可以同时扫描两个完全独立的包,或者应用多个独立的过滤器来排除或包含特定的组件。在本小节的示例中,使用@ComponentScans一次性扫描了com.example.demo.bean1和com.example.demo.bean2两个包,成功地将BeanA和BeanB扫描并注入到Spring的ApplicationContext中。
8. 组件扫描的组件名称生成
当我们在Spring中使用注解进行bean的定义和管理时,通常会用到@Component, @Service, @Repository, @Controller等注解。在使用这些注解进行bean定义的时候,如果我们没有明确指定bean的名字,那么Spring会根据一定的规则为我们的bean生成一个默认的名字。
这个默认的名字一般是类名的首字母小写。例如,对于一个类名为MyService的类,如果我们像这样使用@Service注解:
@Service public class MyService { }
那么Spring会为我们的bean生成一个默认的名字myService。我们可以在应用的其他地方通过这个名字来引用这个bean。例如,我们可以在其他的bean中通过@Autowired注解和这个名字来注入这个bean:
@Autowired private MyService myService;
这个默认的名字是通过BeanNameGenerator接口的实现类AnnotationBeanNameGenerator来生成的。AnnotationBeanNameGenerator会检查我们的类是否有明确的指定了bean的名字,如果没有,那么它就会按照类名首字母小写的规则来生成一个默认的名字。
8.1 Spring是如何生成默认bean名称的(源码分析)
为了解释这个过程,让我们看一下 AnnotationBeanNameGenerator 类的源码,以下源码对应的Spring版本是5.3.7。
先给出源码图片,后面给出源码分析

代码块提出来分析:
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) { if (definition instanceof AnnotatedBeanDefinition) { // 该行检查BeanDefinition是否为AnnotatedBeanDefinition String beanName = this.determineBeanNameFromAnnotation((AnnotatedBeanDefinition)definition); // 该行调用方法来从注解获取bean名称 if (StringUtils.hasText(beanName)) { // 检查是否获取到了有效的bean名称 return beanName; // 如果有,返回这个名称 } } return this.buildDefaultBeanName(definition, registry); // 如果没有从注解中获取到有效的名称,调用方法生成默认的bean名称 }
再看看determineBeanNameFromAnnotation方法

这段代码很长,我们直接将代码块提出来分析:
@Nullable protected String determineBeanNameFromAnnotation(AnnotatedBeanDefinition annotatedDef) { // 1. 获取bean定义的元数据,包括所有注解信息 AnnotationMetadata amd = annotatedDef.getMetadata(); // 2. 获取所有注解类型 Set<String> types = amd.getAnnotationTypes(); // 3. 初始化bean名称为null String beanName = null; // 4. 遍历所有注解类型 Iterator var5 = types.iterator(); while(var5.hasNext()) { // 4.1 获取当前注解类型 String type = (String)var5.next(); // 4.2 获取当前注解的所有属性 AnnotationAttributes attributes = AnnotationConfigUtils.attributesFor(amd, type); // 4.3 只有当前注解的属性不为null时,才会执行以下代码 if (attributes != null) { Set<String> metaTypes = (Set)this.metaAnnotationTypesCache.computeIfAbsent(type, (key) -> { Set<String> result = amd.getMetaAnnotationTypes(key); return result.isEmpty() ? Collections.emptySet() : result; }); // 4.4 检查当前注解是否为带有名称的元注解 if (this.isStereotypeWithNameValue(type, metaTypes, attributes)) { // 4.5 尝试从注解的"value"属性中获取bean名称 Object value = attributes.get("value"); if (value instanceof String) { String strVal = (String)value; // 4.6 检查获取到的名称是否为有效字符串 if (StringUtils.hasLength(strVal)) { // 4.7 如果已经存在bean名称并且与当前获取到的名称不一致,则抛出异常 if (beanName != null && !strVal.equals(beanName)) { throw new IllegalStateException("Stereotype annotations suggest inconsistent component names: '" + beanName + "' versus '" + strVal + "'"); } // 4.8 设置bean名称为获取到的名称 beanName = strVal; } } } } } // 5. 返回获取到的bean名称,如果没有找到有效名称,则返回null return beanName; }
最后看看buildDefaultBeanName方法,Spring是如何生成bean的默认名称的。
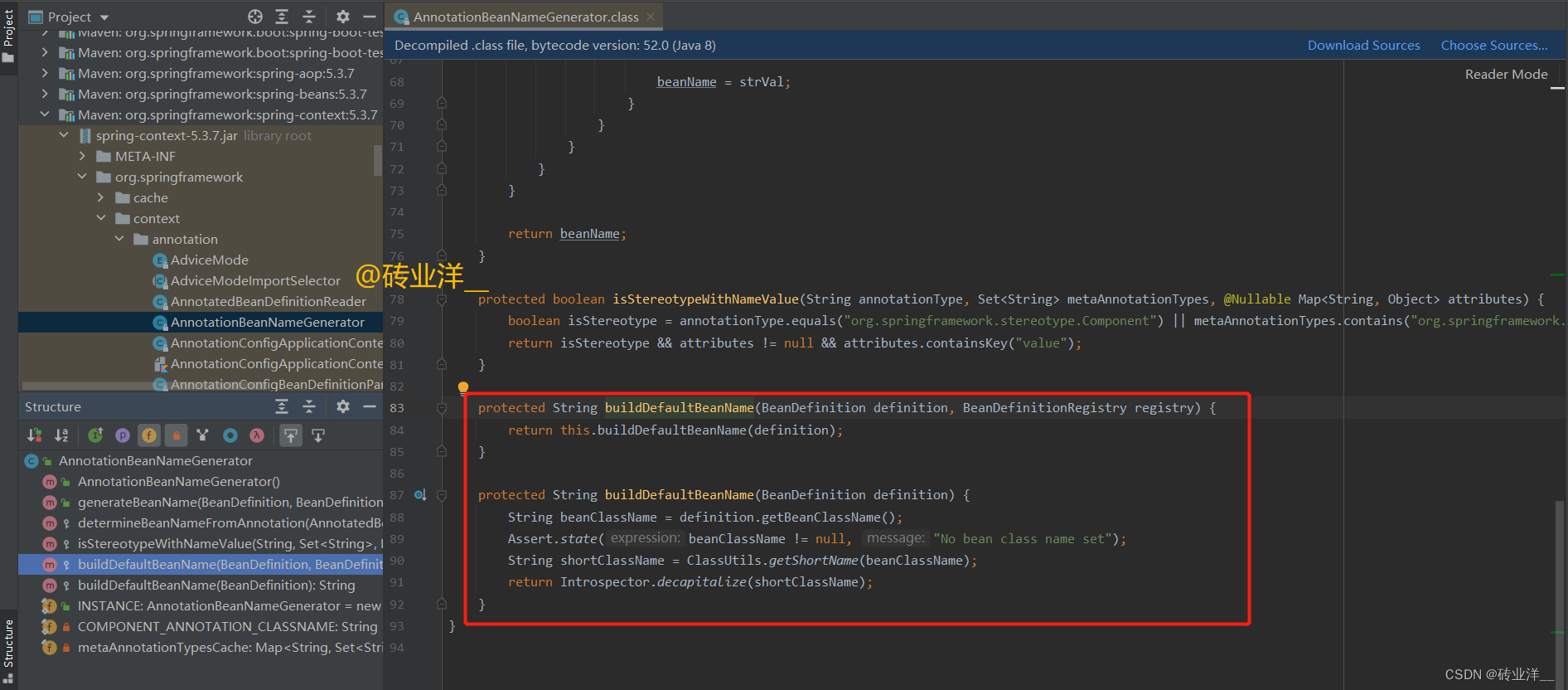
拆成代码块分析:
protected String buildDefaultBeanName(BeanDefinition definition) { // 1. 从bean定义中获取bean的类名 String beanClassName = definition.getBeanClassName(); // 2. 确保bean类名已设置,否则会抛出异常 Assert.state(beanClassName != null, "No bean class name set"); // 3. 使用Spring的ClassUtils获取类的简单名称,即不带包名的类名 String shortClassName = ClassUtils.getShortName(beanClassName); // 4. 使用Java内省工具(Introspector)将类名首字母转换为小写 // 这就是Spring的默认bean命名策略,如果用户没有通过@Component等注解显式指定bean名, // 则会使用该类的非限定类名(即不带包名的类名),并将首字母转换为小写作为bean名。 return Introspector.decapitalize(shortClassName); }
8.2 生成默认bean名称的特殊情况
大家肯定知道UserService默认bean名称为userService,但如果类名为MService,bean名称还是MService,不会首字母小写。具体原因,我们来分析一下。
我们上面分析buildDefaultBeanName方法生成默认bean名称的时候,发现里面有调用decapitalize方法后再返回,我们来看看decapitalize方法。

提出代码块分析一下
/** * 将字符串转换为正常的 Java 变量名规则的形式。 * 这通常意味着将第一个字符从大写转换为小写, * 但在(不常见的)特殊情况下,当有多个字符并且第一个和第二个字符都是大写时,我们将保持原样。 * 因此,“FooBah”变为“fooBah”,“X”变为“x”,但“URL”保持为“URL”。 * 这是 Java 内省机制的一部分,因为它涉及 Java 对类名和变量名的默认命名规则。 * 根据这个规则,我们可以从类名自动生成默认的变量名。 * * @param name 要小写的字符串。 * @return 小写版本的字符串。 */ public static String decapitalize(String name) { if (name == null || name.length() == 0) { return name; } // 如果字符串的前两个字符都是大写,那么保持原样 if (name.length() > 1 && Character.isUpperCase(name.charAt(1)) && Character.isUpperCase(name.charAt(0))) { return name; } char chars[] = name.toCharArray(); // 将第一个字符转为小写 chars[0] = Character.toLowerCase(chars[0]); return new String(chars); }
根据 Java 的命名规则,类名的首字母应该大写,而变量名的首字母应该小写,它告诉内省机制如何从类名生成默认的变量名(或者说 bean 名)。
这里可以看到, decapitalize 方法接收一个字符串参数,然后将这个字符串的首字母转为小写,除非这个字符串的前两个字符都是大写,这种情况下,字符串保持不变。
所以,在Java内省机制中,如果类名的前两个字母都是大写,那么在进行首字母小写的转换时,会保持原样不变。也就是说,对于这种情况,bean的名称和类名是一样的。
这种设计是为了遵守Java中的命名约定,即当一个词作为类名的开始并且全部大写时(如URL,HTTP),应保持其全部大写的格式。
9. Java的内省机制在生成默认bean名称中的应用
Java内省机制(Introspection)是Java语言对Bean类的一种自我检查的能力,它属于Java反射的一个重要补充。它允许Java程序在运行时获取Bean类的类型信息以及Bean的属性和方法的信息。注意:“内省”发音是 "nèi xǐng"。
内省机制的目的在于提供一套统一的API,可以在运行时动态获取类的各种信息,主要涵盖以下几个方面:
-
获取类的类型信息:可以在运行时获取任意一个
Bean对象所属的类、接口、父类、修饰符等信息。 -
属性信息:可以获取
Bean类的属性的各种信息,如类型、修饰符等。 -
获取方法信息:可以获取
Bean类的方法信息,如返回值类型、参数类型、修饰符等。 -
调用方法:可以在运行时调用任意一个
Bean对象的方法。 -
修改属性值:可以在运行时修改
Bean的属性值。
通过这些反射API,我们可以以一种统一的方式来操作任意一个对象,无需对对象的具体类进行硬编码。
在命名规则上,当我们获取一个Bean的属性名时,如果相应的getter或setter方法的名称除去"get"/"set"前缀后,剩余部分的第一个字母是大写的,那么在转换成属性名时,会将这个字母变为小写。如果剩余部分的前两个字母都是大写的,属性名会保持原样不变,不会将它们转换为小写。
这个规则主要是为了处理一些类名或方法名使用大写字母缩写的情况。例如,对于一个名为"getURL“的方法,我们会得到”URL“作为属性名,而不是”uRL"。
虽然在日常开发中我们可能不会直接频繁使用到Java的内省机制,但在一些特定的场景和工具中,内省机制却发挥着重要作用:
-
IDE和调试工具:这些工具需要利用内省机制来获取类的信息,如类的层次结构、方法和属性信息等,以便提供代码补全、代码检查等功能。
-
测试框架:例如
JUnit这样的测试框架需要通过内省机制来实例化测试类,获取测试方法等信息以进行测试的运行。 -
依赖注入框架:比如
Spring等依赖注入框架需要利用内省机制来扫描类,获取类中的依赖关系定义,并自动装配bean。 -
序列化/反序列化:序列化需要获取对象的类型信息和属性信息来实现对象状态的持久化;反序列化需要利用类型信息来还原对象。
-
日志框架:很多日志框架可以通过内省机制自动获取日志方法所在类、方法名等上下文信息。
-
访问权限判断:一些安全相关的框架需要通过内省判断一个成员的访问权限是否合法。
-
面向接口编程:内省机制使得在面向接口编程的时候可以不需要
hardcode接口的实现类名,而是在运行时定位。
简言之,内省机制的目的是实现跨类的动态操作和信息访问,提高运行时的灵活性。这也使得框架在不知道具体类的情况下,可以进行一些有用的操作。