mit6.828 - lab2笔记
lab2的实验手册带着我们学习操作系统是如何处理内存管理的。lab2将内存管理划分为 物理内存管理、页表管理、内核地址空间划分三个部分。
lab2的学习目标:重点学习内存管理的相关知识,包括内存布局、页表结构、页映射
lab2的学习任务:完成内存管理的相关代码
在lab2中,完全可以跟着实验手册的节奏走,逐步完善内存管理的代码。不过在根据注释补充各个函数的时候,大概率是懵逼的,需要自己多看几遍,总结
环境准备:
实验 2 包含以下新的源文件:
- inc/memlayout.h
- kern/pmap.c
- kern/pmap.h
- kern/kclock.h
- kern/kclock.c
memlayout.h 和 pmap.h 定义了 PageInfo 结构,用于跟踪哪些物理内存页是空闲的。
kclock.c 和 kclock.h 操作 PC 的电池时钟和 CMOS RAM 硬件,其中 BIOS 记录了 PC 所含的物理内存量等信息。
pmap.c 中的代码需要读取这些设备硬件,以计算出物理内存的容量,但这部分代码已经为你完成:你不需要了解 CMOS 硬件工作的细节。
请特别注意 memlayout.h 和 pmap.h,因为本实验要求您使用并理解其中包含的许多定义。您可能还需要查看 inc/mmu.h,因为其中包含的许多定义对本实验也很有用。
Part1:物理内存管理(练习1)
操作系统必须跟踪物理内存中哪些是空闲内存,哪些是当前正在使用的内存。JOS 以页面粒度管理 PC 的物理内存,这样它就可以使用 MMU 来映射和保护每一块已分配的内存。
现在你将编写物理页面分配器来实现物理内存管理。它通过 struct PageInfo 对象的链表来跟踪哪些页面是空闲的,每个对象对应一个物理页面。我们要做的就是通过 PageInfo链表,实现对物理内存的申请、释放。
练习 1. 在 kern/pmap.c 文件中,您必须实现以下函数的代码(可能按照给出的顺序)。
boot_alloc()
mem_init()(只调用到 check_page_free_list(1))。
page_init()
page_alloc()
page_free()
check_page_free_list() 和 check_page_alloc() 对物理页面分配器进行测试。你应该启动 JOS 并查看 check_page_alloc() 是否报告成功。修改代码,使其通过测试。你可能会发现添加自己的 assert()s 来验证你的假设是否正确很有帮助。
为了逐步理解物理页面分配器的工作原理,我们就按照练习1的要求,逐个实现代码就好了,不过在那之前,我们来看一下lab1 最后的物理内存的情况和虚拟地址空间的映射情况:
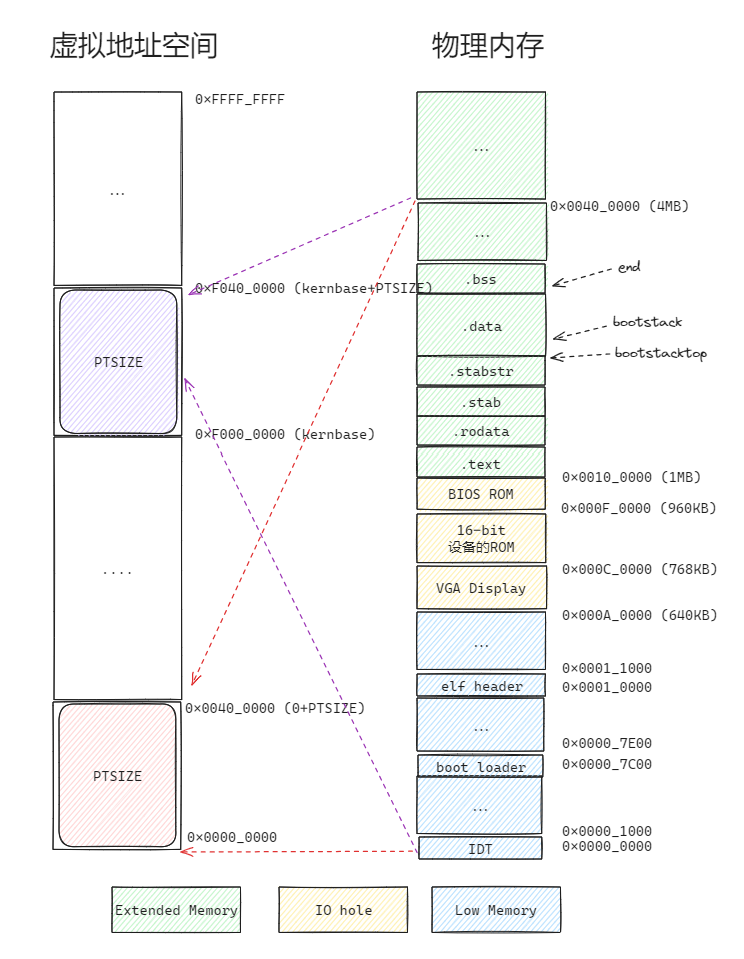
boot_alloc
只在初始化时使用,用来确定申请n子节内存后后,空闲内存的首地址(虚拟内存空间)是多少。
为了让JOS能够追踪空闲内存的首地址究竟是多少,这里使用一个全局变量 nextfree 来记录.
static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
// nextfree 一开始的值应该是多少?当然是kernel.ld中的标号end所指的位置,即内核加载进内存后的尾部
if (!nextfree) {
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
// 分配一块足够放下n个字节的地址块,然后将这个地址块的地址返回。
// 注意地址块必须按照 PGSIZE 对齐
result = nextfree;
// 更新nextfree
nextfree = ROUNDUP((char *)result + n, PGSIZE);
return result;
}
完事了之后,按照 练习1 的指引,我们看一眼 mem_init
mem_init
mem_init 是用来初始化内存管理的函数。物存管理的部分在前面被处理,大致工作流程为:
- 获取硬件信息,内存有多大,i386_detect_memory();
- 初始化页目录 kern_pgdir
- 初始化pages数组
// Set up a two-level page table:
// kern_pgdir is its linear (virtual) address of the root
//
// This function only sets up the kernel part of the address space
// (ie. addresses >= UTOP). The user part of the address space
// will be set up later.
//
// From UTOP to ULIM, the user is allowed to read but not write.
// Above ULIM the user cannot read or write.
void
mem_init(void)
{
uint32_t cr0;
size_t n;
// Find out how much memory the machine has (npages & npages_basemem).
i386_detect_memory();
// Remove this line when you're ready to test this function.
// panic("mem_init: This function is not finished\n");
//////////////////////////////////////////////////////////////////////
// create initial page directory.
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
//////////////////////////////////////////////////////////////////////
// Recursively insert PD in itself as a page table, to form
// a virtual page table at virtual address UVPT.
// (For now, you don't have understand the greater purpose of the
// following line.)
// Permissions: kernel R, user R
kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
//////////////////////////////////////////////////////////////////////
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// Your code goes here:
pages =(struct PageInfo *) boot_alloc(sizeof(struct PageInfo)*npages);
memset(pages, 0, sizeof(struct PageInfo) * npages);
//////////////////////////////////////////////////////////////////////
// Now that we've allocated the initial kernel data structures, we set
// up the list of free physical pages. Once we've done so, all further
// memory management will go through the page_* functions. In
// particular, we can now map memory using boot_map_region
// or page_insert
page_init();
check_page_free_list(1);
check_page_alloc();
check_page();
//....
}
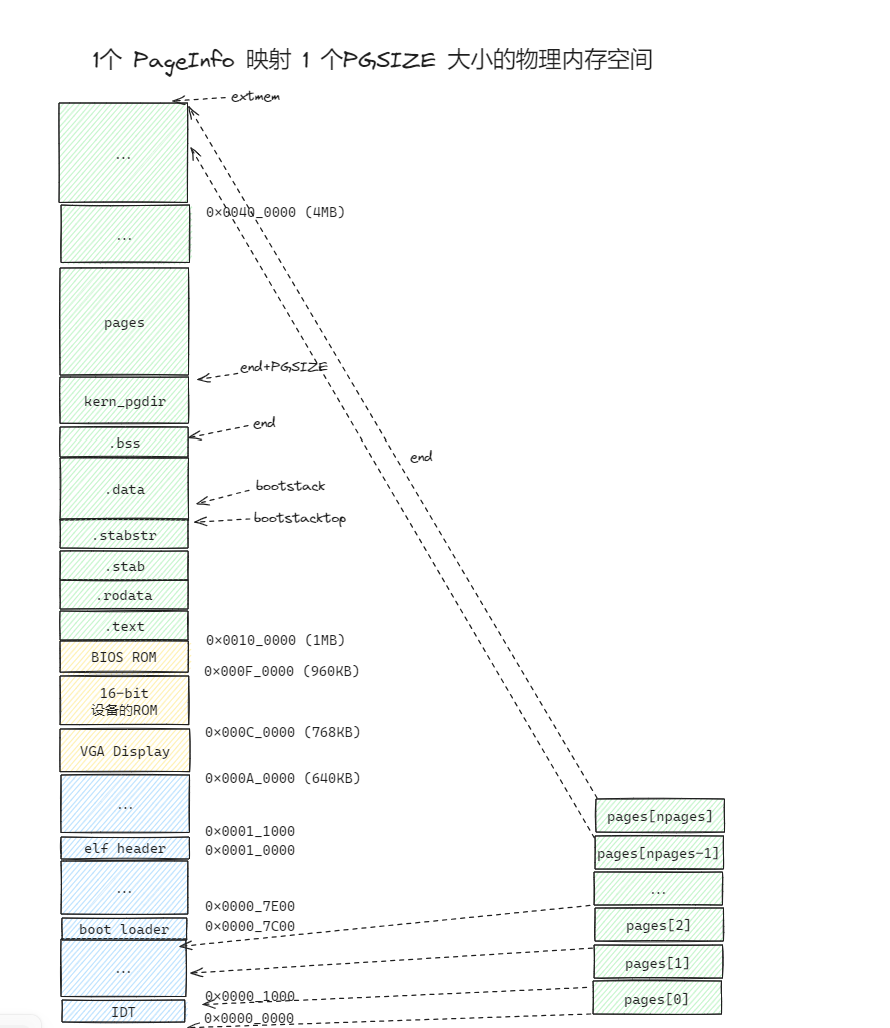
在完成了 mem_init刀 page_init 之前的代码后,整理一下目前的物理内存和 虚拟地址空间的映射情况:
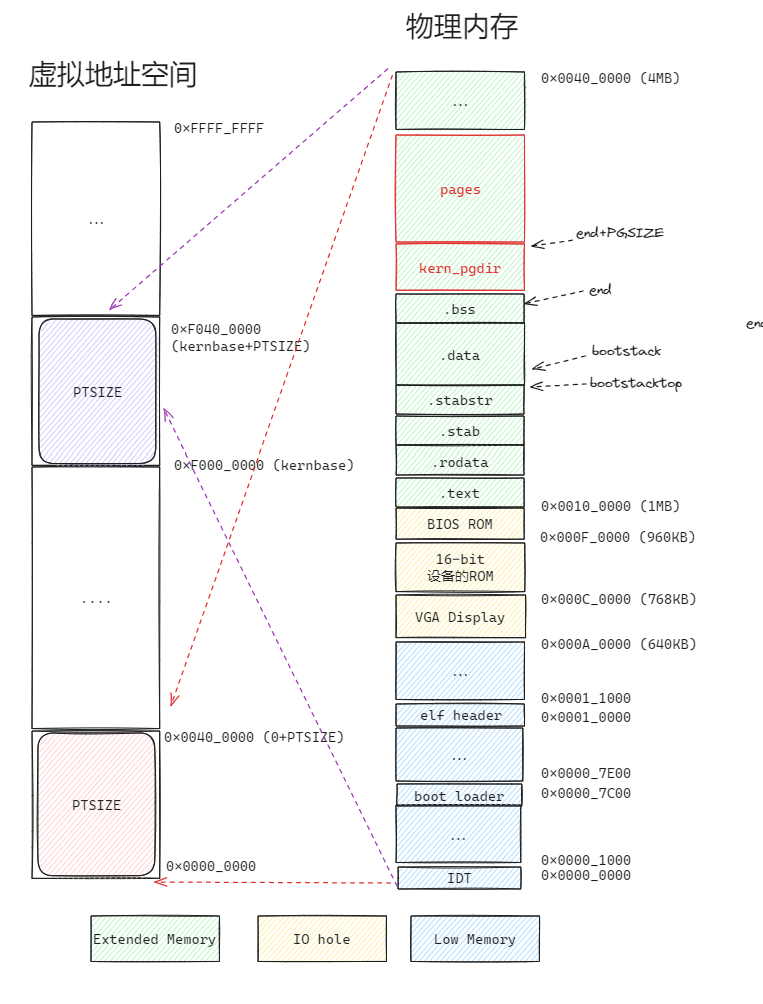
目前我们对 PageInfo 的了解还不足够,在研究page_init之前,有必要学习下 struct PageInfo 的具体细节。
struct PageInfo
先来看看 PageInfo 这个结构体,这个注释真棒。
/*
* 页面描述符结构,映射到 UPAGES。
* 内核可读写,用户程序只读。
*
* 每个结构 PageInfo 保存一个物理页面的元数据。
* 它不是物理页面本身,但物理页面和结构 PageInfo 之间有一一对应的关系。
* 您可以使用 kern/pmap.h 中的 page2pa() 将结构 PageInfo * 映射到相应的物理地址。
*/
struct PageInfo {
//空闲列表中的下一页。
struct PageInfo *pp_link;
// pp_ref 是指向此页的指针(通常是页表条目)的计数。
// 对于使用 page_alloc 分配的页面,pp_ref 是指向该页面的指针计数(通常在页表项中)。
// 在启动时使用 pmap.c 的boot_alloc 分配的页面没有有效的引用计数字段。
uint16_t pp_ref;
}
如注释所述, PageInfo 和物理内存是一一对应的,一个PageInfo 对应一页物理内存(4KB),可以从 page2pa 这个映射函数中看出来
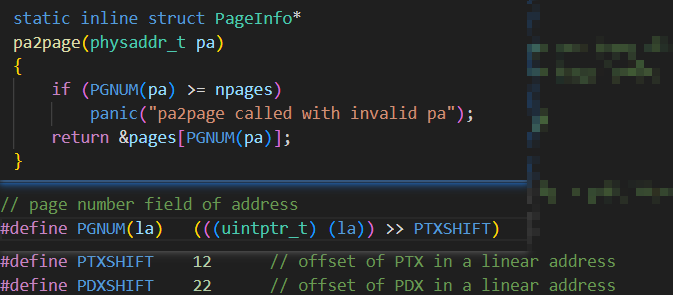
对于一个物理地址 pa ,将其右移 12 位,然后就可以作为 pages 数组的下标了。
也就是说 :
pages[0] 对应 pa 0x0000_0000 到 0x0000_1000
pages[1] 对应 pa 0x0000_1000 到 0x0000_2000
pmap.h 中还有很多好用的函数和宏,除了这个 pa2page 还有 PADDR、KADDR等,可以先看一看,理解下。
理解了 struct PageInfo 的结构和映射方法,可以来看 page_init 了。
page_init
page_init 初始化了 pages 数组,注释给的相当详尽了。按照上面mem_init总结的图写,可以参照 lab1笔记 中的内存布局和 memlayout.h 中关于 IOPHYSMEM、EXTPHYSMEM 的定义写。
// 初始化页面结构和内存空闲列表。
// 完成后,永远不要再使用 boot_alloc。 只使用下面的页面分配器函数来分配和取消分配物理内存。
// 通过 page_free_list 分配和删除物理内存。
//
void
page_init(void)
{
// 这里的示例代码将所有物理页面标记为空闲。
// 但实际情况并非如此。 哪些内存是空闲的?
// 1) 将物理页 0 标记为使用中。
// 这样,我们就可以保留实际模式 IDT 和 BIOS 结构,以备不时之需。 (目前还不需要,但是......)。
//
// 2) 其余的基本内存 [PGSIZE, npages_basemem * PGSIZE)是空闲的。
//
// 3) 然后是 IO 孔 [IOPHYSMEM, EXTPHYSMEM),它必须永远不会被分配。
//
// 4) 然后是扩展内存 [EXTPHYSMEM, ...) 其中一些在使用中,一些是空闲的。
// 内核在物理内存的哪里?哪些物理页已经用于页表和其他数据结构?
//
// 修改代码以反映这一点。
// 注意:切勿实际触及与空闲页面对应的物理内存!
//
size_t i;
//物理页 0 标记为使用中
pages[0].pp_ref = 1;
for(int i = 1; i<PGNUM(IOPHYSMEM); i++){
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
//然后是 IO 孔 [IOPHYSMEM, EXTPHYSMEM),它必须永远不会被分配。
for(int i = PGNUM(IOPHYSMEM); i<PGNUM(EXTPHYSMEM); i++){
pages[i].pp_ref = 1;
}
//获取当前空闲的内存首地址 cur_free_paddr(物理内存)
physaddr_t cur_free_paddr = PADDR(boot_alloc(0));
//[EXTPHYSMEM, cur_free_paddr) 中的扩展内存在使用中
for(int i = PGNUM(EXTPHYSMEM); i<PGNUM(cur_free_paddr); i++){
pages[i].pp_ref = 1;
}
//[cur_free_paddr, ...] 之后的物理内存目前是空闲的
for(int i = PGNUM(cur_free_paddr); i<npages; i++){
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
page_alloc
从pageinfo 空闲链表中摘下一个,并返回,细节见注释:
//
// 分配一个物理页面。 如果(alloc_flags & ALLOC_ZERO),则用“\0 ”字节填充返回的整个物理页
// 不要增加页的引用,page_alloc 的调用者负责增加页面的引用(显式地或通过 page_insert)。
//
// 务必将已分配页面的 pp_link 字段设置为 NULL,以便page_free 可以检查是否存在双重引用。
//
//
// 如果没有可用内存,则返回 NULL。
//
// Hint: use page2kva and memset
struct PageInfo *
page_alloc(int alloc_flags)
{
// Fill this function in
if(page_free_list == NULL){
return NULL;
}
//取出一个空闲 pageinfo
struct PageInfo * pp = page_free_list;
page_free_list = page_free_list->pp_link;
pp->pp_link = NULL;
//置零
if(alloc_flags & ALLOC_ZERO){
void* pp_kv = page2kva(pp);
memset(pp_kv, 0, PGSIZE);
}
return pp;
}
page_free
//
// 返回一个页面到空闲列表。
// (只有当 pp->pp_ref 达到 0 时才调用此函数)。
//
void
page_free(struct PageInfo *pp)
{
// 填充此函数
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
if(pp->pp_ref != 0 || pp->pp_link != NULL){
panic("page_free: pp->pp_ref is nonzero or pp->pp_link is not NULL.");
}
pp->pp_link = page_free_list;
page_free_list = pp;
}
到此为止,练习1就算完成了,然后测试一下
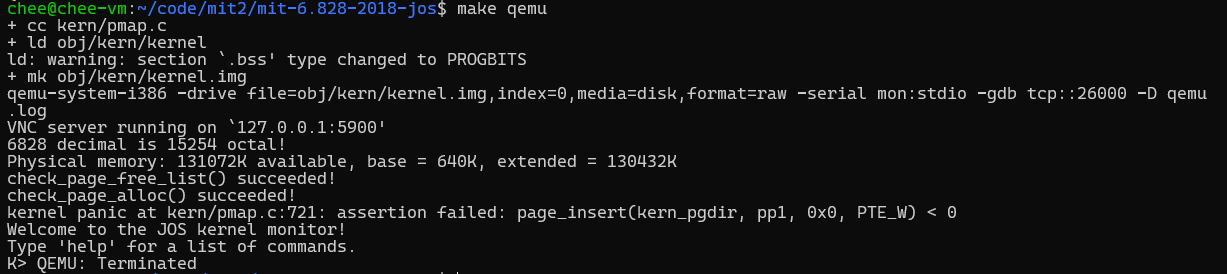
没毛病
Part2:虚拟内存
Part2的核心是页表管理,经过Part1我们可以完成了对 PageInfo 链表 page_free_list 和 数组 pages 的维护。其中pages 存储了所有的Pageinfo对象,page_free_list则记录了空闲的物理页。通过链表能够更方便的分配和释放,通过数组可以轻松的完成PageInfo到其对应的物理页地址的映射。
在进行这一节的学习前,需要了解关于 x86 保护模式的知识。主要是关于分段和页转换方面的,练习2的内容即学习 80386手册中的相关章节。这部分手册写的很好,这里简单翻译了一下,已经了解了的话直接跳到 2.2页表管理
2.1 前置知识
练习 2. 如果您还没有阅读《英特尔 80386 参考手册》
[《英特尔 80386 参考手册》](https://pdos.csail.mit.edu/6.828/2018/readings/i386/toc.htm)第 5 章和第 6 章,请阅读这两章。仔细阅读有关页面转换和基于页面的保护的章节(5.2 和 6.4)。我们建议你也略读一下有关分段的章节;虽然 JOS 使用分页硬件来实现虚拟内存和保护,但在 x86 上无法禁用分段转换和基于分段的保护,因此你需要对其有基本的了解。
关于虚拟地址、线性地址、物理地址
在 x86 术语中,虚拟地址 virtual address 由段选择器和段内偏移量组成。线性地址 linear address是在段转换后、页转换前得到的地址。物理地址 physical address 是经过段和页转换后最终得到的地址,也是最终通过硬件总线到达 RAM 的地址。
Selector +--------------+ +-----------+
---------->| | | |
| Segmentation | | Paging |
Software | |-------->| |----------> RAM
Offset | Mechanism | | Mechanism |
---------->| | | |
+--------------+ +-----------+
Virtual Linear Physical
C 指针是虚拟地址的 “偏移 ”部分。在 boot/boot.S 中,我们安装了全局描述符表 (GDT),通过将所有段基址设置为 0 和将限制设置为 0xffffffffff,有效地禁用了段转换。因此,“选择器 ”不起作用,线性地址始终等于虚拟地址的偏移量。在实验 3 中,我们将不得不与分段进行更多交互,以设置权限级别,但至于内存转换,我们可以在整个 JOS 实验中忽略分段,而只关注页面转换。
记得在实验室 1 的第 3 部分中,我们安装了一个简单的页表,这样内核就可以在 0xf0100000 的链接地址上运行,尽管它实际上是加载在 ROM BIOS 上方 0x00100000 的物理内存中。这个页表只映射了 4MB 的内存。在本实验室为 JOS 设置的虚拟地址空间布局中,我们将扩展虚拟地址空间布局,以映射从虚拟地址 0xf0000000 开始的前 256MB 物理内存,并映射虚拟地址空间的其他一些区域。
练习 3. 虽然 GDB 只能通过虚拟地址访问 QEMU 的内存,但在设置虚拟内存时检查物理内存往往很有用。查看实验工具指南中的 QEMU 监视器命令,尤其是 xp 命令,它可以让你检查物理内存。要访问 QEMU 监视器,请在终端按下 Ctrl-a c(同样的绑定返回串行控制台)。
使用 QEMU 监视器中的 xp 命令和 GDB 中的 x 命令检查相应物理地址和虚拟地址的内存,确保看到的数据相同。
我们的 QEMU 补丁版本提供的 info pg 命令也很有用:它显示了当前页表的紧凑而详细的信息,包括所有映射的内存范围、权限和标志。Stock QEMU 还提供了 info mem 命令,可显示虚拟地址的映射范围和权限概览。
从 CPU 上执行的代码来看,一旦我们进入保护模式(在 boot/boot.S 中首先进入),就无法直接使用线性地址或物理地址。所有内存引用都被解释为虚拟地址,并由 MMU 进行转换,这意味着 C 语言中的所有指针都是虚拟地址。
例如,在物理内存分配器中,JOS 内核经常需要将地址作为不透明值或整数来处理,而不对其进行取消引用。这些地址有时是虚拟地址,有时是物理地址。为了帮助记录代码,JOS 源代码区分了这两种情况:uintptr_t 类型代表不透明的虚拟地址,physaddr_t 代表物理地址。这两种类型实际上只是 32 位整数(uint32_t)的同义词,因此编译器不会阻止你将一种类型赋值给另一种类型!由于它们都是整数类型(而不是指针),如果你试图取消引用,编译器会发出抱怨。
JOS 内核可以通过先将 uintptr_t 转换为指针类型来取消引用 uintptr_t。相比之下,内核无法合理地取消引用物理地址,因为 MMU 会翻译所有内存引用。如果将 physaddr_t 转换为指针类型并取消引用,也许可以加载和存储到得到的地址(硬件会将其解释为虚拟地址),但很可能得不到想要的内存位置。
| C type | Address type |
|---|---|
T* |
Virtual |
uintptr_t |
Virtual |
physaddr_t |
Physical |
JOS 内核有时需要读取或修改只知道物理地址的内存。例如,向页表添加映射可能需要分配物理内存来存储页目录,然后初始化该内存。但是,内核无法绕过虚拟地址转换,因此无法直接加载和存储到物理地址。JOS 从虚拟地址 0xf0000000 的物理地址 0 开始重映射所有物理内存的原因之一,就是帮助内核读写只知道物理地址的内存。为了将物理地址转换为内核可以实际读写的虚拟地址,内核必须在物理地址上加上 0xf0000000,才能在重映射区域找到相应的虚拟地址。你应该使用 KADDR(pa) 来完成这一加法。
有时,JOS 内核还需要根据内核数据结构所在内存的虚拟地址来查找物理地址。内核全局变量和由 boot_alloc() 分配的内存位于内核加载区域,从 0xf0000000 开始,也就是我们映射所有物理内存的区域。因此,要将该区域的虚拟地址转换为物理地址,内核只需减去 0xf0000000。你应该使用 PADDR(va) 来做减法。
参考计数
在今后的实验中,您经常会同时在多个虚拟地址(或多个环境的地址空间)中映射同一个物理页。您将在与物理页对应的结构 PageInfo 的 pp_ref 字段中记录每个物理页的引用次数。当某个物理页面的引用次数为零时,就可以释放该页面,因为它已不再被使用。一般来说,这个计数应该等于物理页在所有页表中出现在 UTOP 以下的次数(UTOP 以上的映射大多是由内核在启动时设置的,永远不会被释放,所以没有必要对它们进行引用计数)。我们还将用它来记录指向页面目录页面的指针数量,以及页面目录对页面表页面的引用数量。
使用 page_alloc 时要小心。它返回的页面的引用计数始终为 0,因此一旦对返回的页面进行了操作(例如将其插入页表),就应该立即递增 pp_ref。有时会由其他函数处理(例如 page_insert),有时则必须由调用 page_alloc 的函数直接处理。
2.2 页表管理
Part2 虚拟内存的关键就在于页表管理。Part1 我们通过 pages 实现了 PageInfo 对象和真实物理内存的 1对1 映射。而页表管理则是实现 页表项(pte)和 PageInfo 的 n对1 映射。没错,对于同一个页目录(pgdir,pde组成的数组)来说,一个PageInfo可能被多个pte记录下来(所以PageInfo有个 ref 成员)。
为了实现这样的页表管理,练习4带着我们编写一套例程来管理页表:插入和删除线性到物理映射,并在需要时创建页表页面。
练习 4. 在 kern/pmap.c 文件中,您必须实现以下函数的代码。
pgdir_walk()
boot_map_region()
page_lookup()
page_remove()
page_insert()
从 mem_init() 调用的 check_page(),用于测试页表管理例程。在继续执行之前,应确保它报告成功。
我在做这个练习的时候发现页表管理的 page_insert 和 page_remove 与物存管理的 page_alloc 和 page_free 有点容易混淆。这时候要记住,物存管理的 page_alloc 和 page_free处理的是 pageinfo 到物理页的映射,是1对1映射,我们只要维护page_free_list和pages数组即可。
而页表管理的 page_insert 和 page_remove 处理的是 pte 到 pageinfo的映射,是n对1映射,我们需要维护双层页表结构,以及PageInfo的ref。
pgdir_walk()
给定 pgdir,返回va对应的pte的指针。按照页表的结构,需要:
- 通过va的高10位在pgdir中找 pde,
- 通过pde的高20位找到对应的 pte_table
- 通过va的次高10位,在pte_table 中找 pte
因为 mem_init 的时候,我们实际上只有两个 pte_table。因此上面第2步可能会发现,pte_table还不存在,需要page_alloc。这是唯二需要做pageinfo计数递增操作的地方。另一个计数递增的地方发生在 page_insert中。
// 给定指向页面目录指针 “pgdir”,pgdir_walk 返回指向线性地址 “va ”的页表项 (PTE) 的指针。
// 这需要走两级页表结构。相关的页表页可能还不存在。
// 如果不存在,且 create == false,则 pgdir_walk 返回 NULL。
// 否则,pgdir_walk 将使用 page_alloc 分配一个新的页表页。
// - 如果分配失败,pgdir_walk 返回 NULL。
// - 否则,新页面的引用计数被递增,页面被清空,pgdir_walk 返回一个指向新页表页面的指针。
//
// Hint 1: 可以使用 kern/pmap.h 中的 page2pa() 将 PageInfo * 转换为其引用页的物理地址。
// Hint 2: x86 MMU 同时检查页目录和页表中的权限位,因此页目录中的权限比严格需要的权限更大是安全的。
// Hint 3: 查看 inc/mmu.h,获取用于操作页表和页目录项的有用宏。
//
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// Fill this function in
// 查找va对应的页目录项(PDE)
pde_t * pde_ptr = &pgdir[PDX(va)]; //用数组的形式写更容易理解
// PTE_P没有置位,说明pde_ptr对应页表(pte_table)没有分配
if (!(*pde_ptr & PTE_P)) {
if(create){//如果对应的pte_table的内存空间还没有申请,则申请空间,并填写pde
struct PageInfo *pp = page_alloc(ALLOC_ZERO);//申请一个物理页
if(pp == NULL){//如果没有物理页了,直接返回NULL
return NULL;
}
pp->pp_ref ++;
//将物理页的“物理地址”填写至pde
*pde_ptr = page2pa(pp) | PTE_U |PTE_W|PTE_P;
}else{
return NULL;
}
}
//PTE_ADDR(*pde_ptr)取pde的前20位,含义是va对应的pte所在pte_talbe的*物理*地址
//注意啊,是物理地址,在这里必须使用KADDR宏,因为代码在执行时会将地址当做虚拟地址处理,即要经过页转换
pte_t *pte_table = KADDR(PTE_ADDR(*pde_ptr));
pte_t * pte_ptr = &pte_table[PTX(va)]; //PTX(va)取va的中间10位,含义是va对应的pte在页表中的索引
return pte_ptr;
}
boot_map_region
//
// 将虚拟地址空间的 [va, va+size) 映射到以 pgdir 为根的页表中的物理地址空间 [pa, pa+size)。
// 大小是 PGSIZE 的倍数,va 和 pa 都是页面对齐的。
// 对条目使用权限位 perm|PTE_P。
//
// 该函数仅用于设置 UTOP 以上的 “静态 ”映射。因此,它不应**改变映射页面上的 pp_ref 字段。
//
// Hint: the TA solution uses pgdir_walk
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
size_t page_num = size / PGSIZE;
if (size % PGSIZE != 0) {
page_num++;
} //计算总共有多少页
for (int i = 0; i < page_num; i++) {
//获取 va 在pgdir中的pte
pte_t *pte_ptr = pgdir_walk(pgdir, (void *)va, 1);//获取va对应的PTE的地址
if (pte_ptr == NULL) {
panic("boot_map_region(): out of memory\n");
}
*pte_ptr = pa | PTE_P | perm; //将pa填写到 va对应的pte中
pa += PGSIZE; //更新pa和va,进行下一轮循环
va += PGSIZE;
}
}
page_insert
// 在虚拟地址 “va ”处映射物理页 “pp”。
// 页表项的权限(低 12 位)应设置为 “perm|PTE_P”。
// should be set to 'perm|PTE_P'.
//
// Requirements
// - 如果'va'处已经映射了一个页面,则应将其 page_remove()。
// - 如有必要,应按要求分配一个页表并插入到'pgdir'中。
// - 如果插入成功,pp->pp_ref 应递增。
// - 如果'va'中以前存在页面,则必须使 TLB 失效。
//
// Corner-case hint: 请务必考虑在同一 pgdir 中的同一虚拟地址重新插入同一 pp 时会发生什么情况。
// 不过,尽量不要在代码中区分这种情况,因为这经常会导致微妙的错误;
// 有一种优雅的方法可以在一条代码路径中处理所有问题。
//
// RETURNS:
// 0 on success
// -E_NO_MEM, if page table couldn't be allocated
//
// Hint: The TA solution is implemented using pgdir_walk, page_remove,
// and page2pa.
//
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// Fill this function in
pte_t * pte_ptr = pgdir_walk(pgdir, va, 1);
if(pte_ptr == NULL){
return -E_NO_MEM;
}
pp->pp_ref ++;
if((*pte_ptr) & PTE_P){
page_remove(pgdir, va);
}
physaddr_t pa = page2pa(pp);
*pte_ptr = pa | PTE_P | perm;
pgdir[PDX(va)] |= perm;
return 0;
}
page_lookup
// 返回映射到虚拟地址 “va ”的 struct PageInfo。
// 如果 pte_store 不为零,我们将在其中存储该页面的 pte 地址。
// page_remove 使用了这个地址,它可以用来验证系统调用参数的页面权限,但大多数调用者不应该使用它。
//
// 如果在 va 处没有页面映射,则返回 NULL。
//
// Hint: the TA solution uses pgdir_walk and pa2page.
//
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
pte_t * pte_ptr = pgdir_walk(pgdir, va, 0);
if(pte_ptr == NULL||!(*pte_ptr & PTE_P)){
return NULL;
}
physaddr_t pa = PTE_ADDR(*pte_ptr);
struct PageInfo * pp = pa2page(pa);
if(pte_store != NULL){
*pte_store = pte_ptr;
}
return pp;
}
page_remove
// 解映射虚拟地址 “va ”处的物理页。
// 如果该地址处没有物理页,则什么也不做。
//
// Details:
// - 物理页面上的 refcount 应该递减。
// - 如果 refcount 为 0,则释放物理页。
// - 对应于'va'的 pg 表项应设置为 0。
// (如果存在这样的 PTE)
// - 如果从页表中删除一个条目,TLB 必须失效。
//
//
// Hint: The TA solution is implemented using page_lookup,
// tlb_invalidate, and page_decref.
//
void
page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
pte_t * pte_ptr = NULL;
struct PageInfo * pp = page_lookup(pgdir, va, &pte_ptr);
if(pp == NULL){
return ;
}
*pte_ptr = 0;
page_decref(pp);
tlb_invalidate(pgdir, va);
}
到此为止练习4算是结束了。
Part3:内核地址空间
经过Part2,我们拥有了将虚拟地址va映射到物理地址pa的能力(以及取消映射的能力)。Part3我们利用Part2的基础设施,对32位线性地址空间进行规划,将地址空间划分为内核区域(高地址)和用户区域(低地址)。分界线由 inc/memlayout.h 中的 ULIM 符号定义,为内核保留了约 256MB 的虚拟地址空间。
在Lab2,我们先只考虑运行一个进程的情况。在后面完整的JOS,每个进程都会有一个页表,其中内核部分而页表内容都一样,使用相同的虚拟地址,且都映射同一块物理地址;
用户部分使用相同的虚拟内存空间,但是映射的物理地址则不同,是各自的代码。为了实现这一目标,需要进行。
权限和故障隔离
对于每一个进程而言,JOS的内核和用户空间处在同一个地址空间中。为了限制用户代码只能访问用户内存区域,需要使用PTE的标志位,标记用户可以访问的内存区域。
要知道,内核的代码是由我们完成的,我们可以控制,但是操作系统还要加载用户的代码,作为内核的开发者,我们当然不希望每次加载的用户的代码破坏掉内核数据,导致崩溃。也不洗某个进程窃取其他进程的数据。
具体来说:
- 用户进程没有权限访问
ULIM以上的任何内存,而内核则可以读写这些内存。 - 对于地址范围
[UTOP,ULIM),内核和用户环境的权限相同:可读、不可写。该地址范围用于向用户环境公开某些内核数据结构的只读权限。 UTOP以下的地址空间供用户环境使用;用户环境将设置访问该内存的权限。
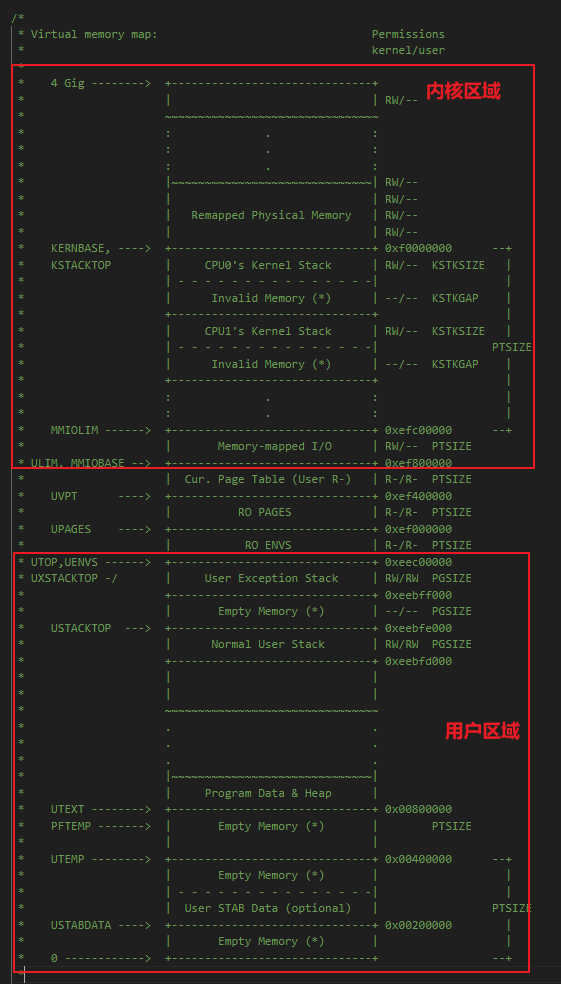
初始化内核地址空间
inc/memlayout.h 显示了你应该使用的布局。你将使用刚才编写的函数来设置适当的线性到物理映射。
练习 5. 填写调用 check_page() 后 mem_init() 中缺失的代码。
现在,您的代码应能通过 check_kern_pgdir() 和 check_page_installed_pgdir() 检查。
//////////////////////////////////////////////////////////////////////
// Now we set up virtual memory
//////////////////////////////////////////////////////////////////////
// 将 “页面 ”映射到线性地址 UPAGES 的用户只读位置
// 权限:
// UPAGES 处的新映像 -- 内核 R、用户 R
// (即 perm = PTE_U | PTE_P)
// - 页面本身 -- 内核 RW,用户 NONE
// 你的代码放在这里:
boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U);
//////////////////////////////////////////////////////////////////////
// 使用 “bootstack ”所指的物理内存作为内核堆栈。 内核堆栈从虚拟地址 KSTACKTOP 开始向下增长。
// 我们认为从 [KSTACKTOP-PTSIZE, KSTACKTOP) 开始的整个范围都是内核堆栈,但将其分成两部分:
// * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- 由物理内存支持
// * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- 没有物理内存支持;
// 所以如果内核堆栈溢出,它将出错而不是覆盖内存。 被称为 “保护页”。
// 权限:内核 RW,用户 NONE
// 你的代码放在这里:
boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W);
//////////////////////////////////////////////////////////////////////
// 将所有物理内存映射到 KERNBASE。
// 也就是说,VA 范围 [KERNBASE, 2^32) 应该映射到 PA 范围 [0, 2^32 - KERNBASE)
// 我们可能没有 2^32 - KERNBASE 字节的物理内存,但我们还是设置了映射。
// 权限:内核 RW,用户 NONE
// Your code goes here:
boot_map_region(kern_pgdir, KERNBASE, 0xffffffff - KERNBASE, 0, PTE_W);
// Check that the initial page directory has been set up correctly.
check_kern_pgdir();
其实,直到目前为止,我们使用的页表还是 lab1 中那个entrypgdir.c 中写死的页表,在lab1中,我们忽略了这个页表的解释,现在可以回来看一看了。
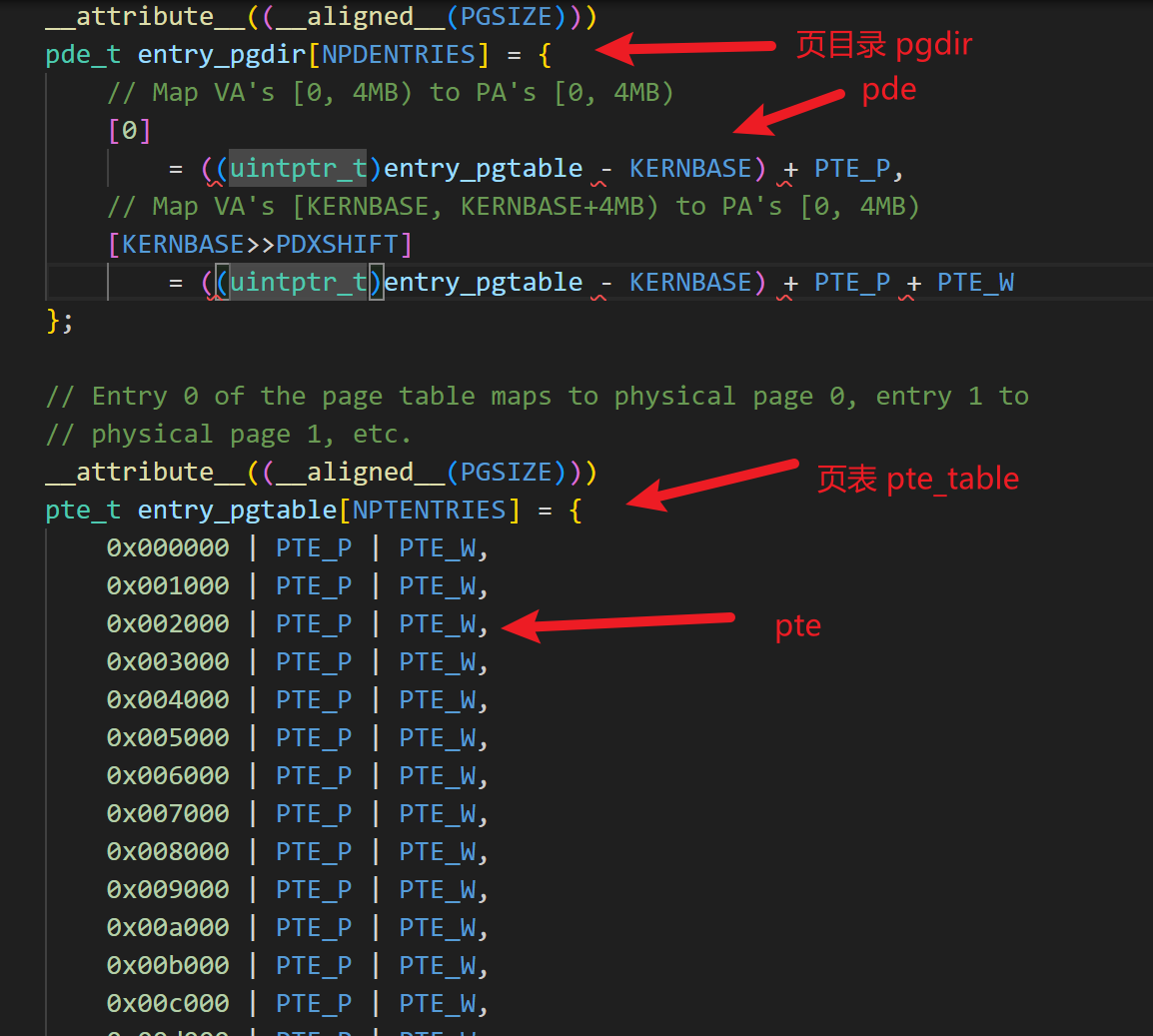
所以说,目前的物理内存和虚拟地址空间的映射关系如下:
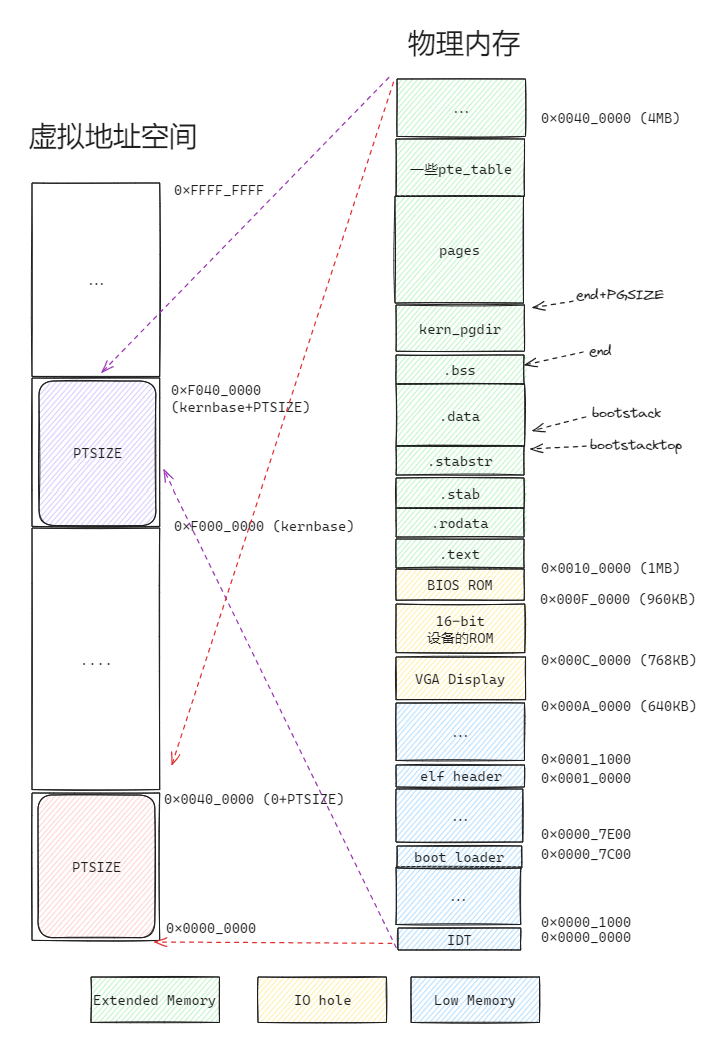
可以看到,在Part1中,物理内存增加了 kern_pgidr和pages。在part2中由于一些内存映射操作(pgdir_walk操作可能为保存新的pte_table而插入物理页),物理内存增加了一些pte_table。
但是左边,地址映射却没有变化。
这是因为,上面的操作完全是对 kern_pgdir这个pde数组做的修改,以及对插入的新pte_table们的修改,我们还没有用修改CR3寄存器,加载我们新的页表 kern_pgdir。
让我们继续将 mem_init 的最后一段看完,
// 从 entry_pgdir 切换到我们刚刚创建的完整 kern_pgdir 页表。
// 我们的指令指针现在应该位于 KERNBASE 和 KERNBASE+4MB 之间的某个位置,这两个页表的映射方式相同。
lcr3(PADDR(kern_pgdir));
check_page_free_list(0);
// entry.S set the really important flags in cr0 (including enabling
// paging). Here we configure the rest of the flags that we care about.
cr0 = rcr0();
cr0 |= CR0_PE|CR0_PG|CR0_AM|CR0_WP|CR0_NE|CR0_MP;
cr0 &= ~(CR0_TS|CR0_EM);
lcr0(cr0);
// Some more checks, only possible after kern_pgdir is installed.
check_page_installed_pgdir();
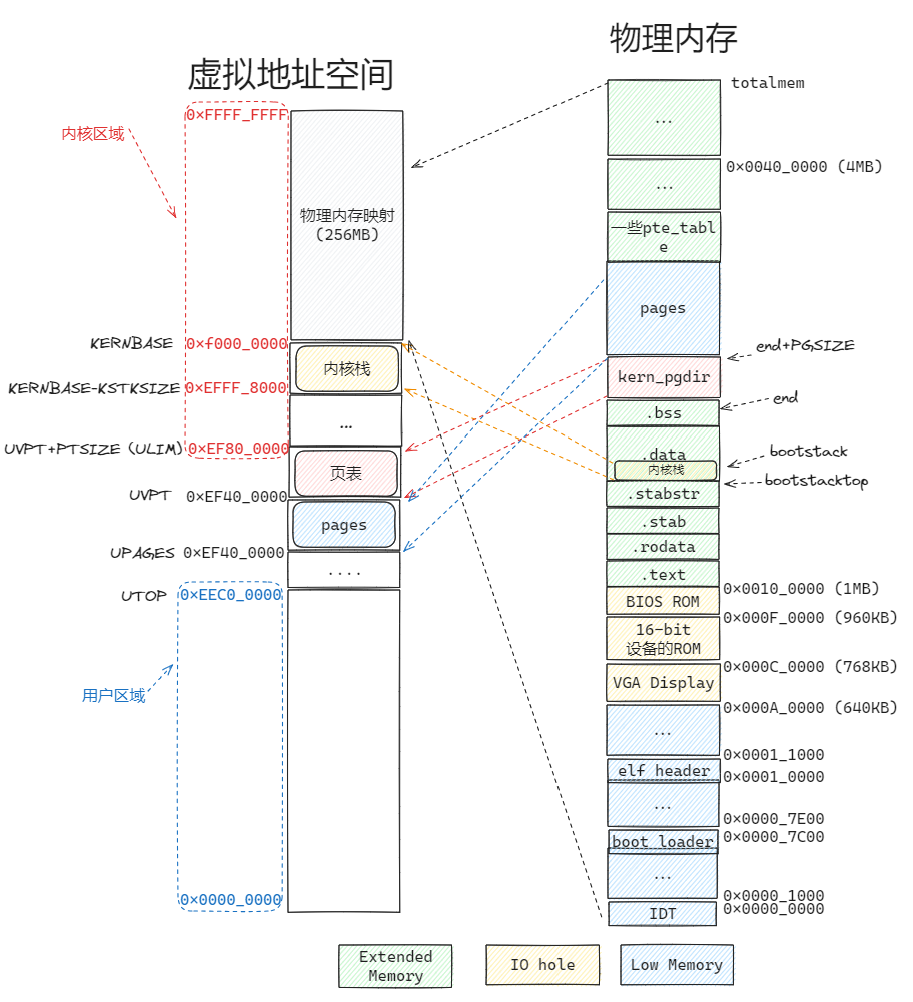
LCR3指令将kern_pgdir加载后,物理内存和虚拟地址空间的映射如下: